Après avoir réalisé des audits SEO pendant plus de 10 ans, j’ai analysé beaucoup de sites web. Au cours des dernières années, j’ai remarqué que de nombreux propriétaires de sites faisaient les mêmes erreurs. J’ai fini par devoir montrer les même erreurs dans presque tous les audits SEO que j’ai réalisés ces dernières années. Ces erreurs sont souvent liées au site en général et au web design. Attention, il s’agit bien d’erreurs concernant le site et non pas le SEO. Cependant, ces erreurs peuvent avoir un impact direct sur le trafic et la visibilité dans les résultats des moteurs de recherche. Il était donc de mon devoir de les faire remarquer à mes clients durant mes audits de SEO technique.
J’appelle ces erreurs des erreurs communes car lors des 2 dernières années, 8 audits de SEO technique sur 10 comportaient au moins 80 % d’entre elles. Prenons donc le temps d’analyser ces 8 erreurs communes. Vous pourrez ainsi vérifier que votre site web ne commet pas certaines d’entre elles. Si vous utilisez OnCrawl, vous pourrez plus facilement identifier et réparer ces problèmes. J’ai détaillé chaque erreur ci-dessous et expliqué pourquoi elles sont importantes et comment utiliser OnCrawl peut vous aider à les corriger.
1. Mauvaise migration HTTP vers HTTPs
2. Problèmes de contenu dupliqué
3. Méga menus et maillage interne
4. Problèmes de structure du site
5. Pages et contenus orphelins
6. Problèmes de liens, liens de faible et mauvaise qualité
7. Sur-optimisation ou sous-optimisation
8. Usage incorrect du code ou des directives
Erreur courante : une mauvaise migration HTTP vers HTTPs
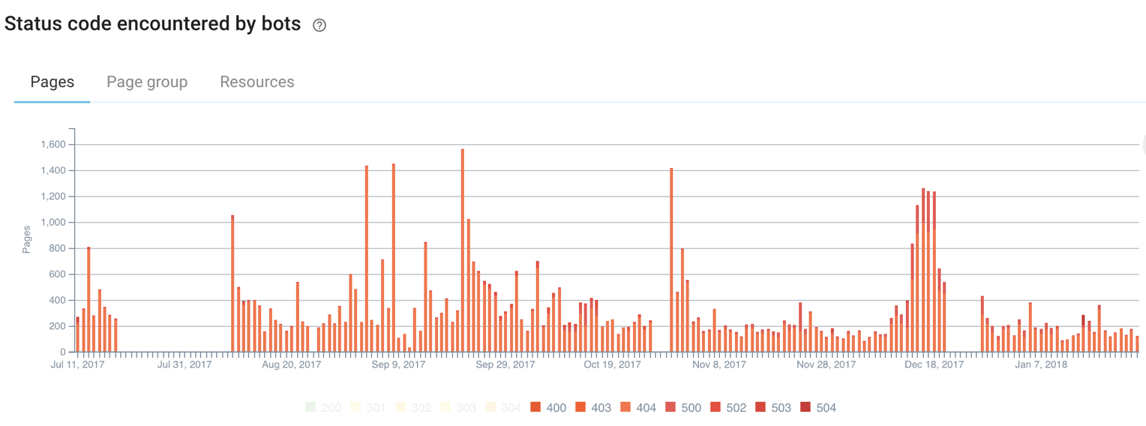
Je vois ce problème non seulement lors de mes audits SEO mais aussi en visitant simplement des sites web. L’indicateur principal de cette erreur est le symbole du cadenas brisé dans la barre du navigateur. Si vous vous rendez sur un site avec ce symbole, cela signifie qu’il a un problème de HTTPs. Lorsque les sites web opèrent leur migration de HTTP to HTTPs (de la version non sécurisée à la version sécurisée SSL), chaque mention et lien interne sur le nom de domaine doit être changé en HTTPs. Cela signifie que si le code source référence une image (tous les sites ont des images), il devrait charger cette image en HTTPs et non HTTP. S’il référence le HTTP comme cela :
< img src=”http://www.oncrawl.com/images/logo.png” alt=”OnCrawl logo” />
la page liée à ce code va montrer le fameux symbole du cadenas brisé. L’URL pour oncrawl.com devrait être en HTTPs et non HTTP comme montré ci-dessus. Une autre erreur liée est le maillage interne et la manière dont les pages sont connectées entre elles sur le site. Une migration de site web de HTTP à HTTPs réussie liera toujours une page à une autre en utilisant une URL HTTPs dans le lien, et non HTTP. Si les liens sur le site apparaissent comme cela :
< a href=” http://www.oncrawl.com/support/”>Contact Support
et renvoient vers l’URL HTTP, alors vous obtiendrez probablement une redirection 301 permanente redirigeant les visiteurs vers https://www.oncrawl.com/support/, c’est-à-dire la version HTTPs de la page. Lors du crawl dusite en utilisant OnCrawl, l’outil va remonter BEAUCOUP de redirections. Si votre migration HTTP vers HTTPs est réussie, vous ne devriez pas trouver de redirections lors du crawl de votre site.
Comment réparer cette erreur courante ?
Globalement, tous vos liens internes et références à votre URL dans le code source de votre site devraient pointer vers la version HTTPs et non pas la version HTTP. Si vous utilisez WordPress, vous pouvez rechercher dans toute la base de données de votre site pour trouver les URLs HTTP (qui incluent le nom de domaine) et les remplacer par la version HTTPs. Vous pouvez aussi faire cela dans d’autres CMS qui ont une base de données. Pour plus d’informations, j’ai récemment couvert ce sujet dans un article sur le blog d’OnCrawl intitulé “Réaliser une migration de domaine sans encombre”.
Erreur courante : les problèmes de contenu dupliqué
Les problèmes liés au contenu dupliqué sont très courants et il est en réalité très difficile d’avoir un site avec 0% de contenu dupliqué. Si vous avez un menu principal sur votre site, celui-ci va apparaître sur toutes les pages, donc il est commun d’avoir au moins un peu de contenu dupliqué. Cependant, le plus souvent, l’erreur découle d’un paragraphe de texte (ou même plus !) qui apparaît sur toutes les pages du site. Par exemple, vous pourriez avoir un paragraphe de texte “À propos de l’entreprise” dans le footer de votre site. Cela ne cause pas de problème majeur à moins que vos pages aient moins de contenu que le paragraphe de texte à propos de votre entreprise dans le footer. Si ce texte est de 200 mots alors que le reste de la page ne comporte pas autant de mots (ce qui est courant) alors le texte du footer va l’emporter sur le contenu de la page. Cela peut devenir un problème si vous avez beaucoup de pages sur votre site.
Je me rappelle d’un site que j’ai audité dans le passé qui avait une sidebar comportant des témoignages récents de clients. La barre déroulait l’intégralité du témoignage, donc les visiteurs ne pouvaient en voir qu’un seul à la fois. Généralement, cela n’est pas un problème mais le code source de la page avait plus de 30 témoignages qui se déroulaient tous un par un. Tous les textes de ces 30 témoignages se chargeaient sur chaque page du site, ce qui représentait 3500 mots de contenu. Aucune des autres pages du site n’avaient plus de 3500 mots. Donc toutes les pages du site avaient les mêmes contenus. Nous avons retiré les témoignages de la sidebar et les classements du site et le trafic ont explosé.
Techniquement, il n’y a pas de pénalités pour le contenu dupliqué à moins qu’il soit tellement présent qu’il entraîne une pénalité de spam de Google. C’est plutôt rare, mais si vous copiez des pages et/ou sites web alors vous devrez probablement déjà le savoir. La plupart des sites ne dupliquent pas leur contenu délibérément, ce qui peut causer des problèmes de crawl. Un site peut facilement gaspiller son budget de crawl à cause du contenu dupliqué. Il est important de diriger les crawlers des moteurs de recherche vers les pages qui sont uniques et ont le meilleur contenu.
Comment réparer cette erreur courante ?
Vous pouvez utilisez la fonctionnalité Duplicate Content d’OnCrawl dans le Crawl Report pour en savoir plus sur la quantité de contenu dupliqué que vous pourriez avoir sur votre site. Si le site a des balises titre, des méta descriptions et des titres dupliqués, par exemple, vous devriez enquêter pour découvrir quelles pages sont des dupliquées. Certains sites WordPress vont générer des pages dupliquées avec des balises, catégories et pages archivées comme les pages par date.
Erreur courante : les méga menus
Combien de liens le site a-t-il dans son menu ? J’ai déjà vu des centaines de liens (plus de 200 ou 300) dans un seul menu principal. Cela empêche non seulement les visiteurs de trouver ce qu’ils recherchent mais en plus ce n’est pas bon pour le SEO en général. Nous parlons de méga menus lorsqu’un site a plus de 10 items déroulants, que chacun d’entre eux a 10 items et que certains de ces items ont eux-mêmes des items de sous menu. Cela signifie que vous avez plus de 100 pages toutes liées entre elles. Ces 100 liens renvoyant directement vers 100 pages différentes.
Des sites comme ceux-là peuvent facilement (et devraient) être ré-évalués : la structure du site est probablement mal catégorisée. J’ai déjà réalisé un audit sur un site e-commerce comportant plus de 300 000 pages produits. Le site vendait des fournitures de bureau, d’église et des équipements sportifs. Vous pouviez littéralement être sur une page vendant des bancs d’église puis passer directement sur une page proposant des tapis de yoga. Je ne connais personne qui passe de l’un à l’autre dans leur processus d’achat.
C’est un exemple extrême mais le menu principal dispose de menus déroulants qui permettent à l’utilisateur de naviguer vers des pages aux sujets différents. Imaginez le site web comme un ensemble de sujets ou de mini sites au sein d’un site plus grand. Il y a une page d’accueil mais celle-ci ne devrait renvoyer que vers les catégories principales. Ces pages de catégories devraient ensuite renvoyer vers des pages avec une thématique similaire. Puis, l’utilisateur doit pouvoir naviguer vers une sous-catégorie et directement vers la page produit. Les visiteurs devraient ensuite pouvoir cliquer sur une autre catégorie avant d’aller sur une page qui n’a plus rien à voir.
Lier 200 pages à 200 pages dans un menu n’est jamais une bonne pratique. S’il s’agit d’un méga menu, alors vous devez le corriger. C’est donc aussi lié à des problèmes globaux de structure du site.
Comment réparer cette erreur courante ?
Il y a plusieurs éléments à vérifier afin de vous débarrasser de ce problème de méga menu :
- Analysez la structure interne de votre site ;
- Vérifiez les silos de contenu (s’ils existent sur listes) ;
- Vérifiez les groupes de contenu. Les pages liées entre elles doivent traiter du même sujet.
Erreur courante : problèmes de structure de site
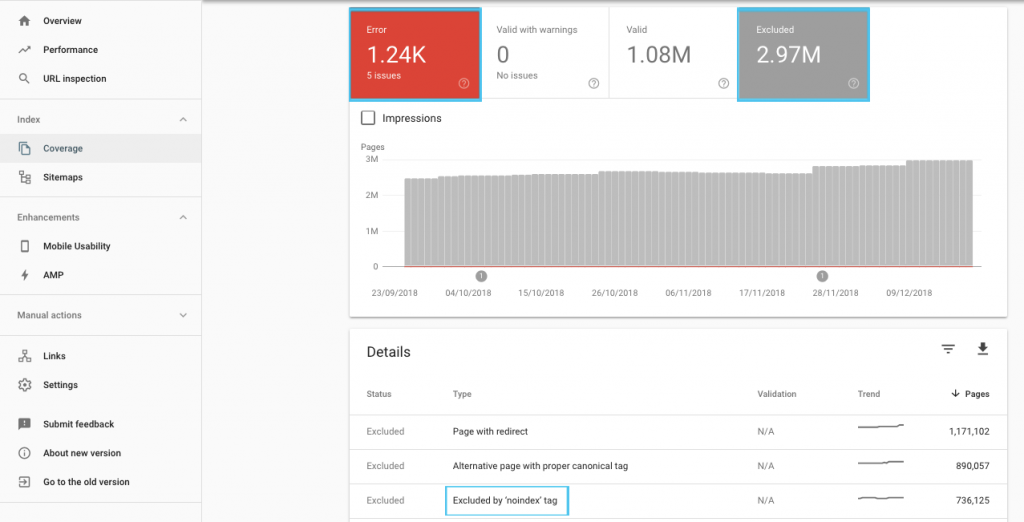
Ce problème est très similaire à celui du méga menu. Si un site dispose d’un méga menu conséquent, alors la structure du site n’est pas idéale. Comme mentionné précédemment, la structure du site doit être pensée de manière à ce que les sujets soient groupés de manière logique. Il est plutôt rare qu’un site dispose d’une page qui soit liée à un sous-thème puis à une catégorie et reçoive toujours des centaines de liens pointant vers elle. Y-a-t-il des pages orphelines sur le site ? Dans le rapport OnCrawl, est-ce que le crawl a relevé des pages orphelines qui ont du trafic et sont indexées mais qui ne sont pas rattachées à la structure du site ?
Comment régler cette erreur courante ?
Jetez un oeil aux rapports de popularité interne d’OnCrawl, vérifiez les groupes de pages par profondeur, la distribution d’Inrank et le flux d’Inrank. Est-ce que le site a un méga menu sur sa page d’accueil ? Est-ce que le lien du méga menu renvoie vers des pages de sous-catégories ? Il ne devrait pas. Au lieu de cela, vous devriez avoir un petit nombre de pages catégories liées dans le menu principal de la page d’accueil.
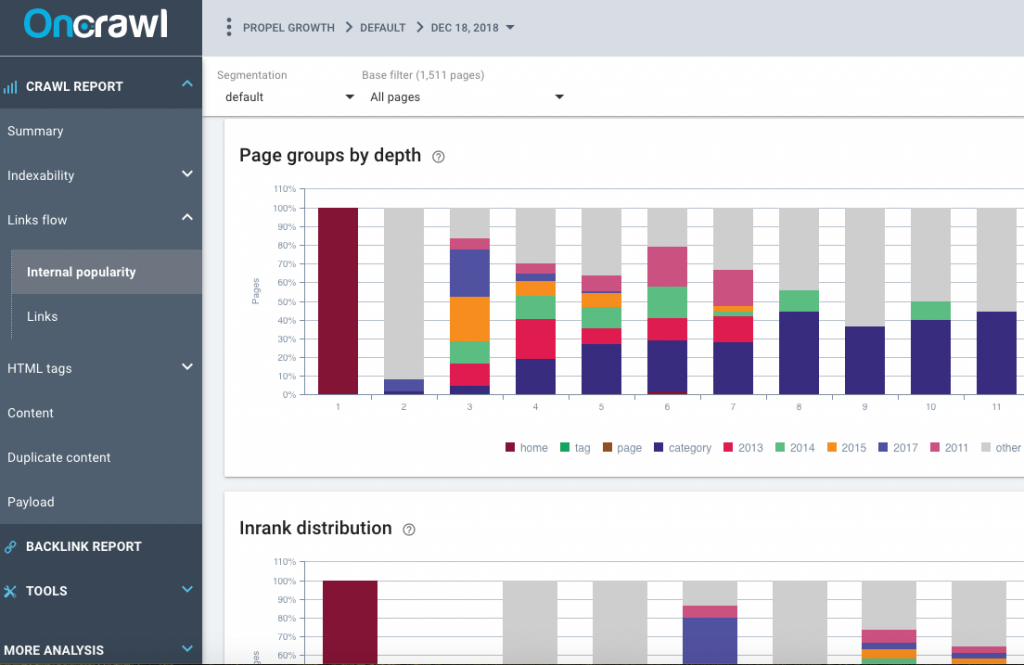
Y-a-t-il des sujets clairs ou des sections sur le site ? Cela va demander une analyse manuelle de votre site, vous devriez pouvoir dire plutôt facilement s’il n’y a qu’un méga menu avec toutes les pages du site ou s’il y a des sections. Vérifiez également la section Links du rapport OnCrawl.
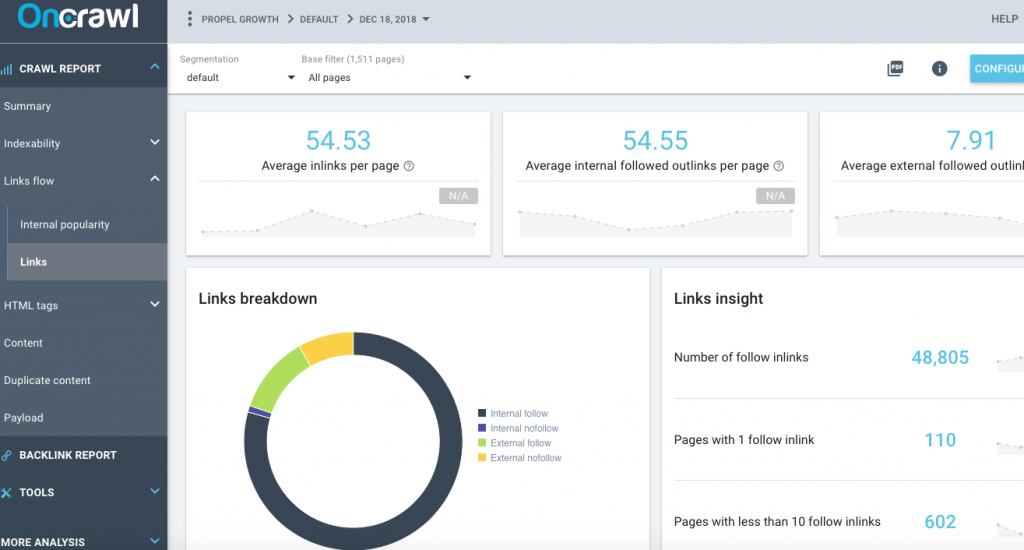
Remarquez le nombre moyen de liens entrants par page et les liens sortants suivis par page. Il devrait normalement y avoir plus de liens entrants sur les pages que de pages sortantes. Si ces nombres sont proches, ou s’il y a plus de liens sortants que de liens entrants, alors il peut y avoir un problème de structure. Est-ce qu’il y a des pages sur le site avec moins de 10 liens follow ? Est-ce qu’il y a des pages orphelines qui ne sont pas rattachées à la structure du site ?
Erreur courante : les pages et contenus orphelins
Les pages orphelines sont plus courantes que ce que vous pensez. Lorsque le crawler commence à parcourir votre site depuis la page d’accueil et suivre tous les liens qu’il trouve, il ne pourra quand même jamais atteindre une page orpheline car elle n’est pas liée à la structure. Ces pages sont détectées par OnCrawl grâce aux données de Google Analytics, de la Google Search Console et des logs. OnCrawl identifie les pages qui ne sont pas liées au site et les marque comme des pages orphelines. Elles sont en fait plus courantes que ce que vous pourriez penser car les propriétaires de site opèrent souvent des refontes et laissent les pages sur le serveur sans les lier au site. Cela peut être une ancienne version du site, ou du contenu non approprié pour une nouvelle version. Pourtant, ces pages existent encore sur le site même si elles ne sont pas liées directement au site. C’est une réalité et les pages orphelines peuvent recevoir beaucoup de trafic et très bien se positionner.
Comment réparer cette erreur courante ?
Il existe plusieurs techniques pour réparer ce problème courant. En fait, si vous fournissez les bonnes données à OnCrawl, comme les données de Google Analytics, de Majestic, de la Google Search Console et des logs, l’outil identifiera les pages orphelines. Donc, fournissez les bonnes données et vous détecterez toutes vos pages orphelines. Les données de log peuvent être très importantes, car elles peuvent révéler d’autres facteurs et vous aider à récupérer des pertes de trafic et de classements.
Pour corriger cette erreur courante, identifiez les pages orphelines qui sont importantes puis liez-les correctement au site. Vous devriez notamment les relier à votre structure si elles comportent des liens provenant d’autres sites. Vous pouvez voir cela grâce aux données de Majestic. Les liens vers les pages orphelines qui sont liées au site peuvent passer de l’Inrank et du PageRank aux autres pages du site, les aidant ainsi à se classer.
Erreur courante : problèmes de liens et liens de faible ou mauvaise qualité
Analysez les chiffres du Domain Trust Flow et du Domain Citation de Majestic. Généralement, le Trust Flow devrait être au moins plus grand de 10 points que le Citation Flow. Si le Citation Flow est plus grand que le Trust Flow, vous pourriez avoir des liens de faible qualité pointant vers votre site. Faites en sorte d’avoir des liens de qualité pointant vers votre site plutôt que des liens de faible qualité provenant de sites non fiables. Il est commun d’avoir des liens de mauvaise qualité pointant vers votre site, car vous ne pouvez pas contrôler tous les sites qui décident de renvoyer vers vos pages. Cependant, nous pouvons contrôler certains des liens.
Comment réparer cette erreur courante ?
Prenez le temps de vérifier tous les liens de votre site ! Analysez également la liste des pages qui reçoivent des liens. Est-ce qu’il y a des pages qui reçoivent des liens mais qui ne sont pas redirigées ? Peut-être qu’il y a une vieille page qui n’existe plus et qui dispose de liens ? Je vous conseille de ramener le contenu de la page sur une même URL ou d’implémenter une redirection 301 pour renvoyer vers une page traitant du même sujet. Ainsi, vous devriez récupérer ces liens.
Erreur courante : sur-optimisation ou sous-optimisation
L’optimisation on-page d’un autre temps est une autre erreur fréquente. Les meilleures pratiques SEO actuelles ne sont pas suivies et généralement cela résulte en du bourrage de mots-clés, des métadonnées mal écrites (balises titres ou méta description) ou même par un usage inapproprié des balises titres.
Comment réparer cette erreur courante ?
Il est plutôt simple de réparer ce problème : il suffit d’apprendre les meilleures pratiques pour l’écriture des balises titre, meta et d’utiliser un code HTML acceptable. Les listes ordonnées, les puces, l’utilisation de gras, d’italique et des bonnes polices et couleurs sont obligatoires de nos jours. Nettoyer le code HTML et utiliser le bon code de balisage (Schema.org ou JSON-LD) peut vous aider à obtenir de meilleurs classements et plus de trafic des moteurs de recherche.
Erreur courante : l’usage incorrect du code ou des directives
Abuser du Schema.org ou bien utiliser les mauvais codes peut conduire à une action manuelle de Google. Bien que les données structurées soient un bon point pour votre SEO, elles doivent être implémentées correctement ou vous vous exposez à de sérieuses conséquences. De nombreux sites n’utilisent aucun balisage structuré et il s’agit d’une opportunité manquée de nos jours.
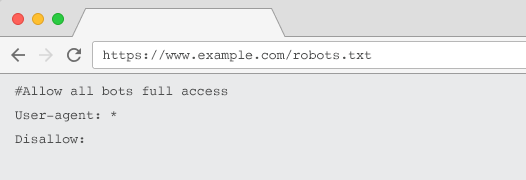
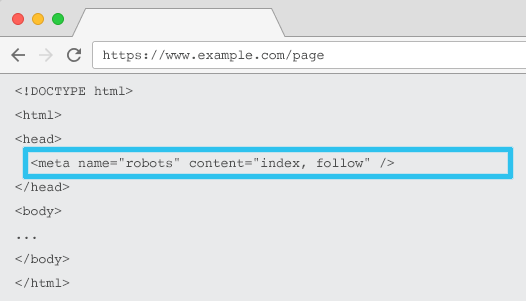
D’autres problèmes liés peuvent impliquer une configuration incorrecte du code ou même des conflits de directives sur des pages. Par exemple, si vous utilisez une balise canonique sur une page alors n’empêchez pas les moteurs de recherche de crawler cette page dans le fichier robots.txt. S’ils ne peuvent pas crawler la page, alors ils ne pourront pas voir la balise canonique.
Voici d’autres exemples d’implémentations de code ou des conflits de directives que je vois régulièrement :
- Usage incorrect des rel next/prev
- Des directives de balises canoniques incorrectes
- Des directives de robots.txt incorrectes
Comment réparer cette erreur courante ?
Honnêtement, pour pouvoir repérer et réparer ces problèmes, vous devez être capable de comprendre ce que chacune de ces directives fait et pourquoi elles sont utilisées. Vous n’avez pas besoin d’être développeur pour comprendre le code schema.org mais vous devez comprendre pourquoi et comment il est utilisé. Je ne suis pas développeur mais je peux copier/coller du code et il existe de nombreux générateurs de code pour vous aider dans cette procédure.
En conclusion
Nous faisons tous des erreurs et heureusement certaines d’entre elles sont réparables. Prendre le temps de les corriger conduira à un site mieux optimisé et adapté aux moteurs de recherche et aux visiteurs. Un audit SEO efficace, même s’il est fait par vous sur votre site, va probablement révéler au moins une de ces erreurs, peut-être plus. Personnellement, j’ai réalisé des audits sur mes sites et trouvé des problèmes que je ne connaissais pas avant mais que j’ai pu réparer grâce à des outils comme OnCrawl. Cependant, il est important de prioriser ses actions car certaines des erreurs trouvées n’ont pas toutes le même impact sur vos performances.
[Read More ...]
 John
John 








{kind=link}
{kind=link}
{kind=link}