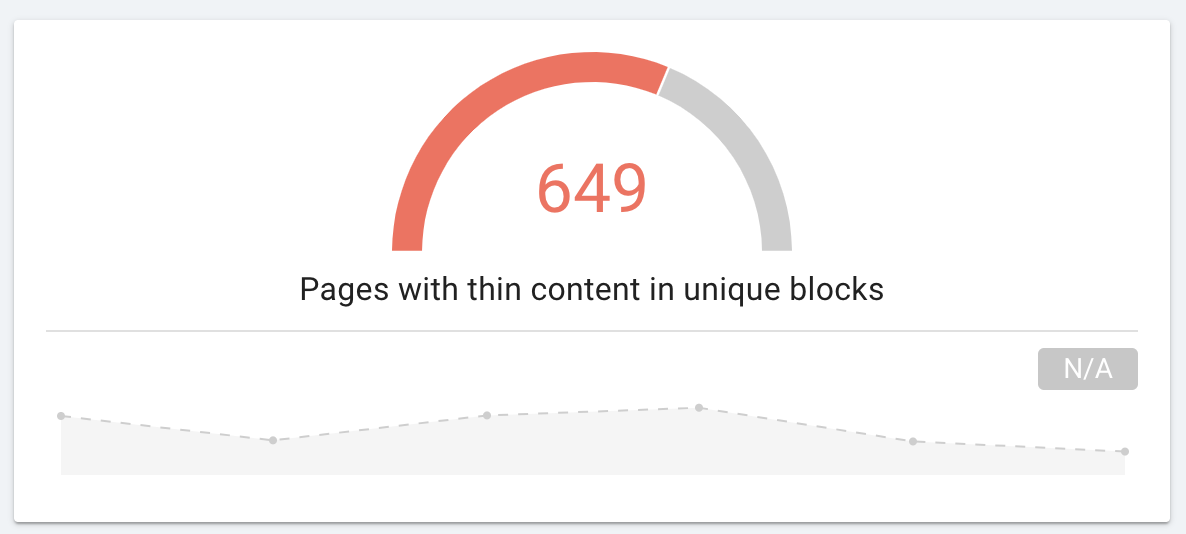
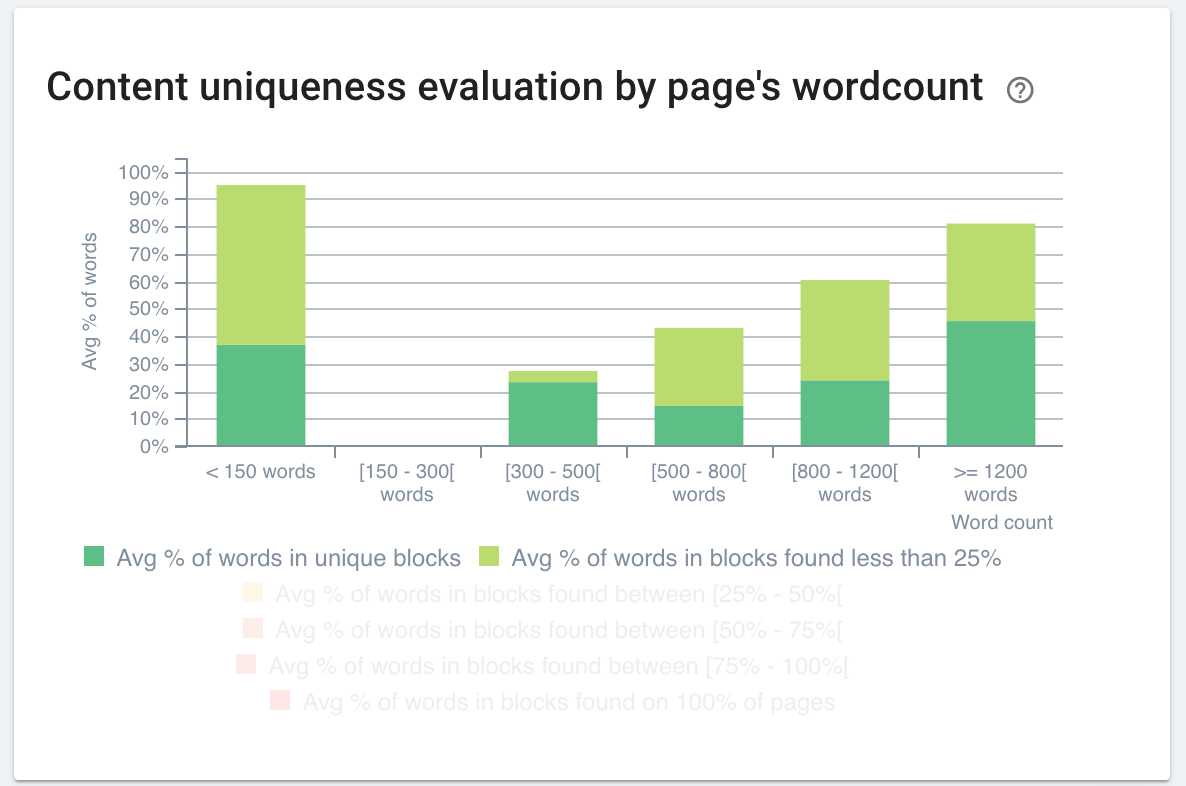
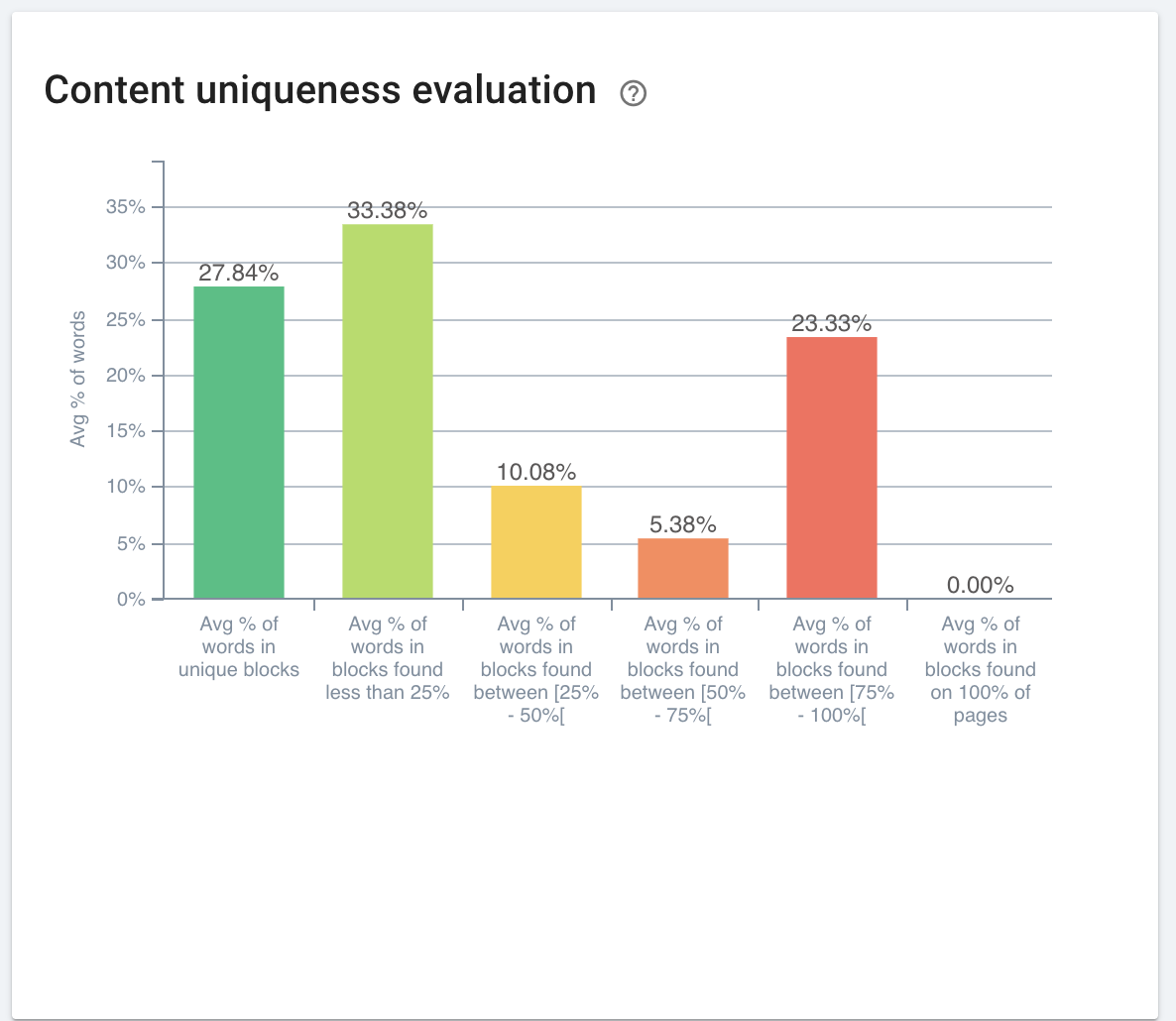
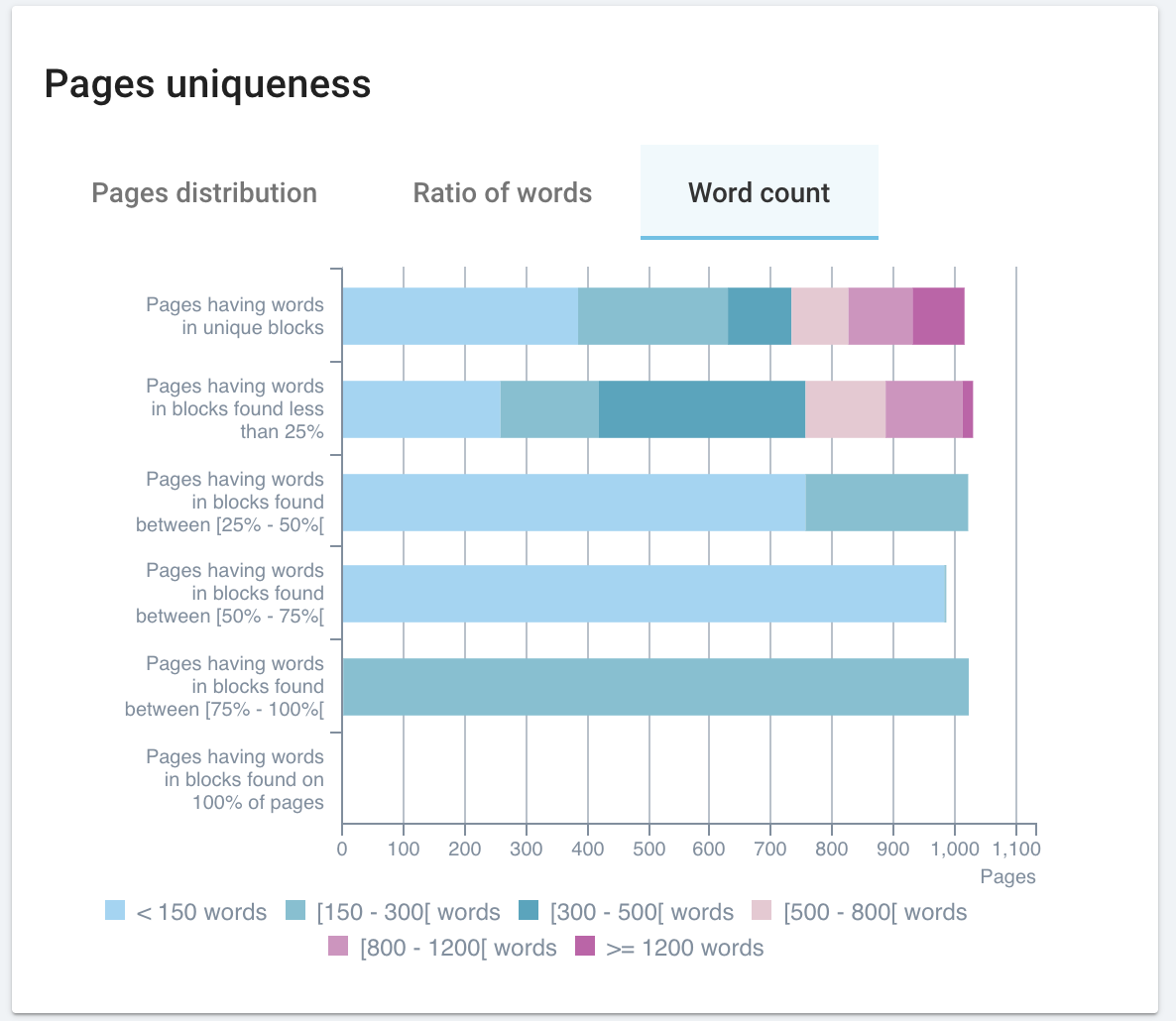
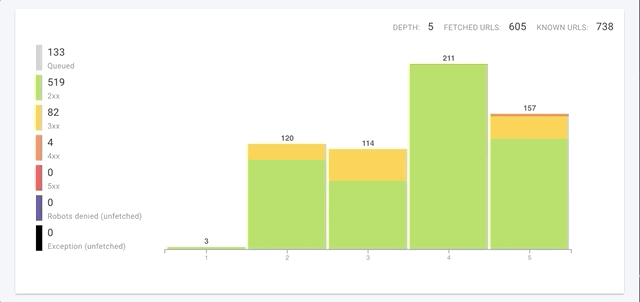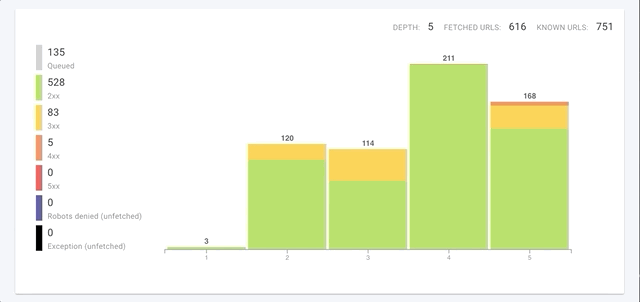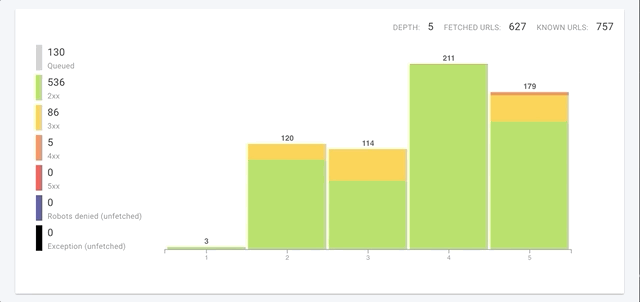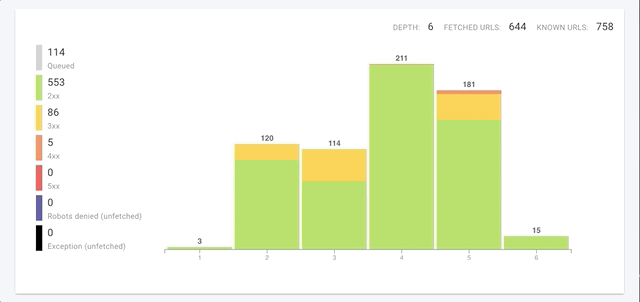
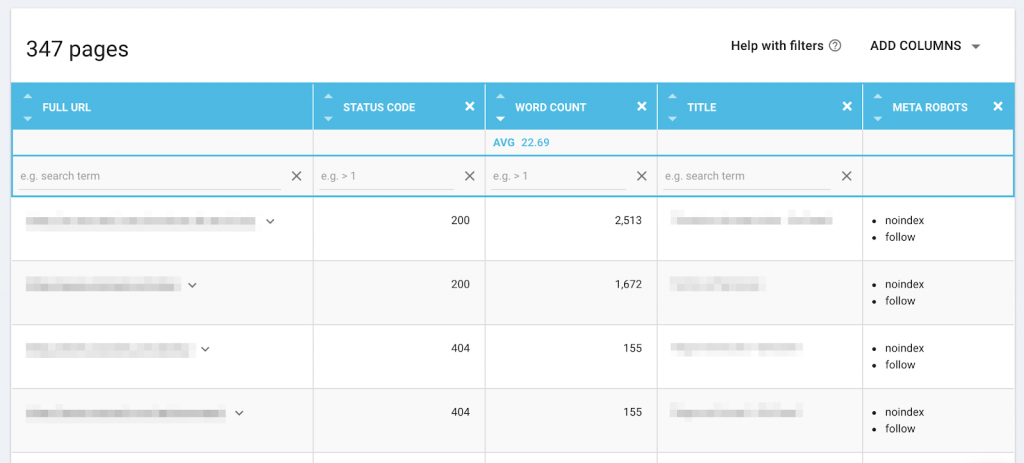
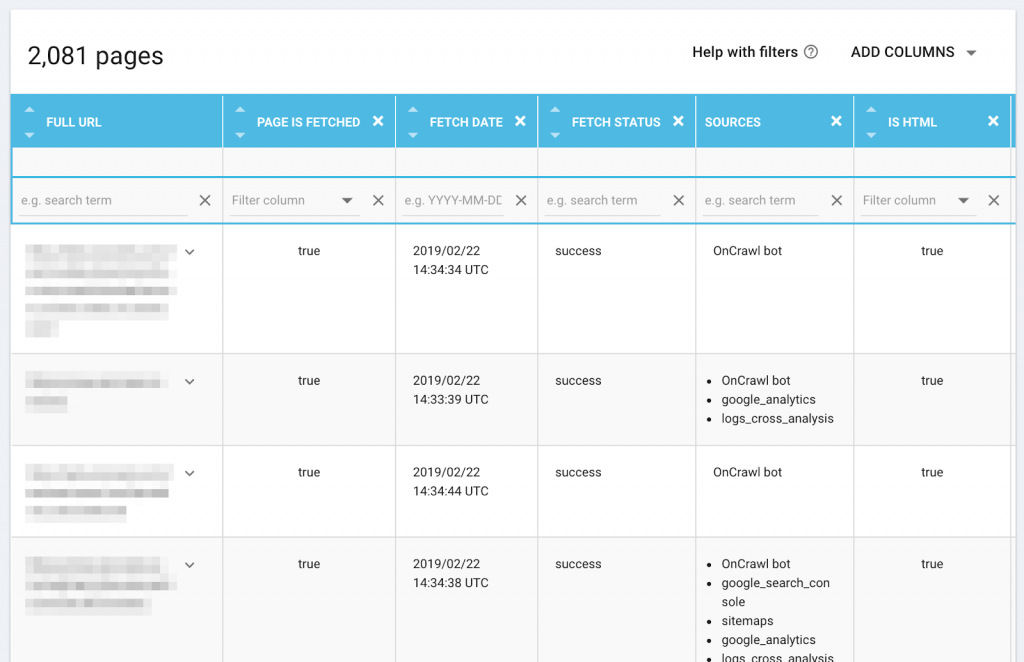
Google identifie du contenu dupliqué sur votre site et rejette les URLs canoniques que vous avez déclarées ? Cela peut arriver lorsque vous ne traitez correctement qu’une partie des pages identifiées par Google comme dupliquées.
Grâce à cet article explicatif sur le traitement et le reporting des pages dupliquées dans OnCrawl, nous espérons vous fournir une nouvelle façon d’aborder la gestion du contenu dupliqué sur votre site web. Cette technique est rapide à mettre en place : vous n’avez besoin que d’un crawl ! Et également rapide à analyser : il faut simplement être capable d’identifier les couleurs d’un feu de circulation et de jauger les tailles de rectangles.
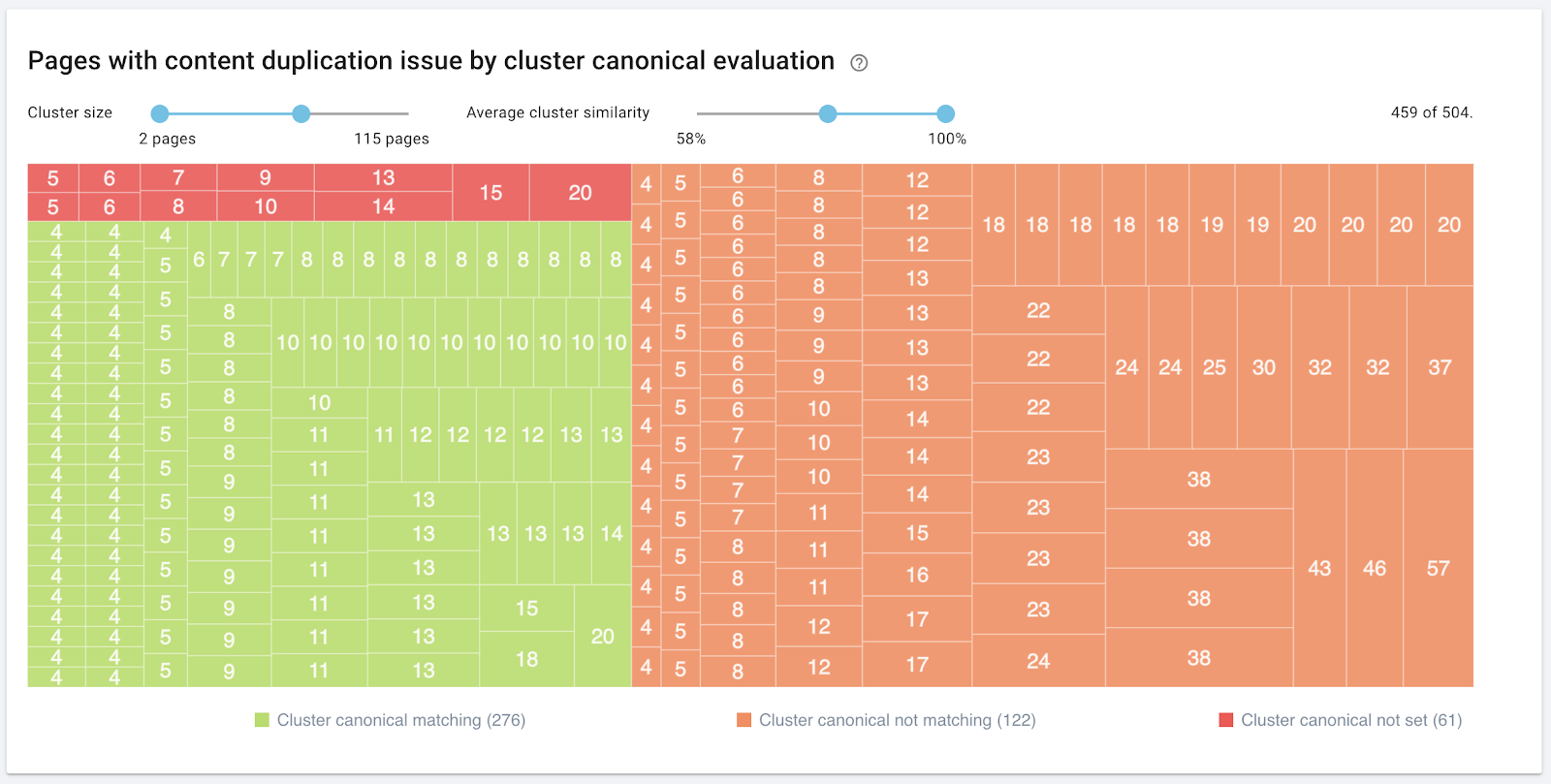
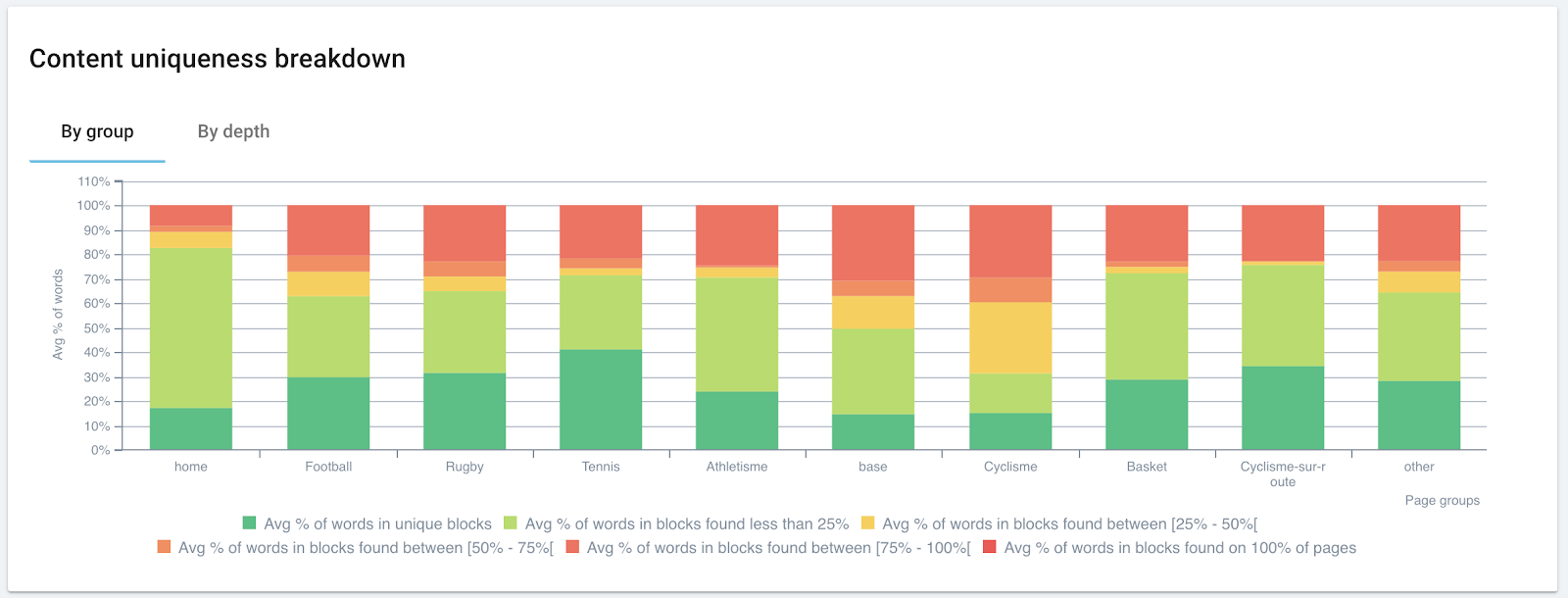
Analyser le contenu dupliqué avec OnCrawl
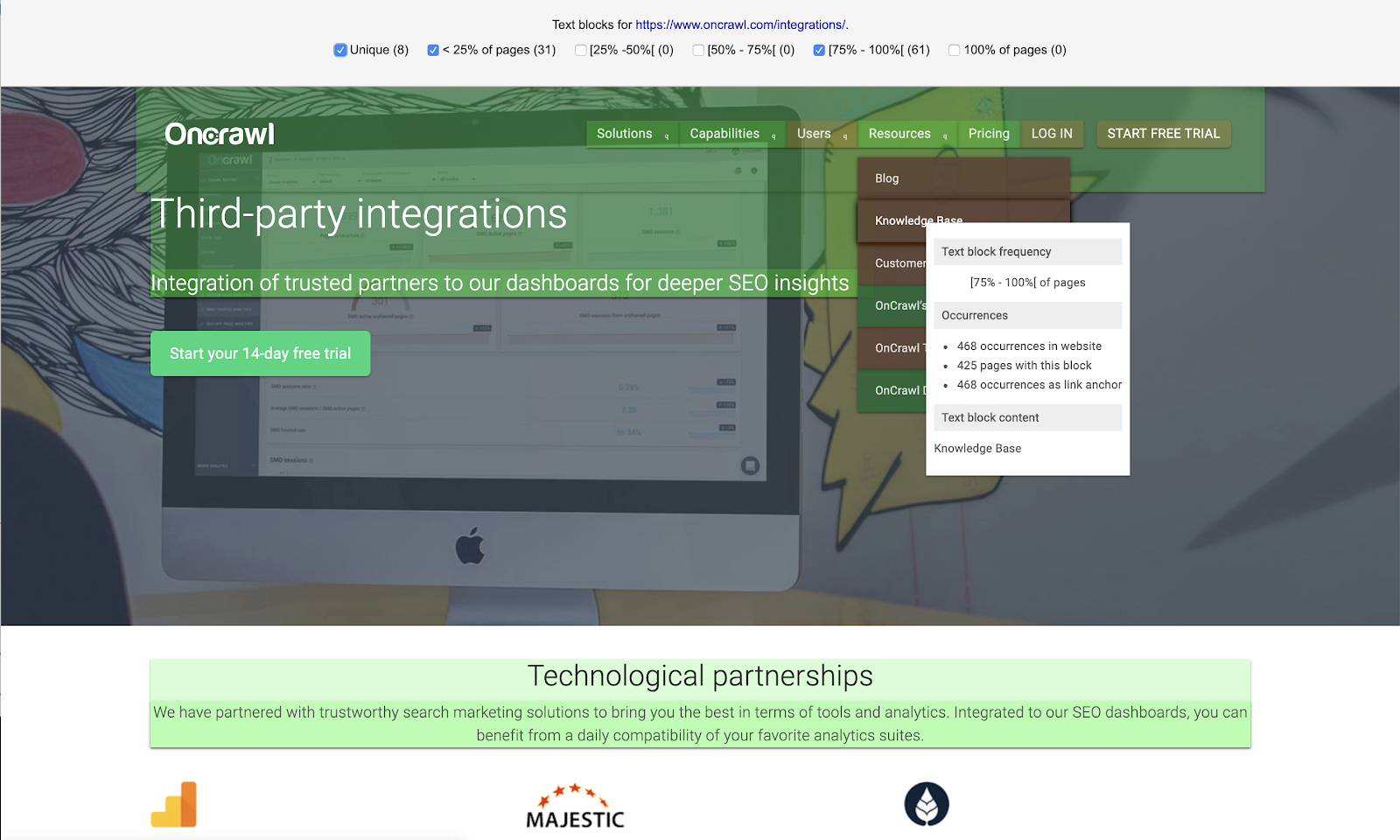
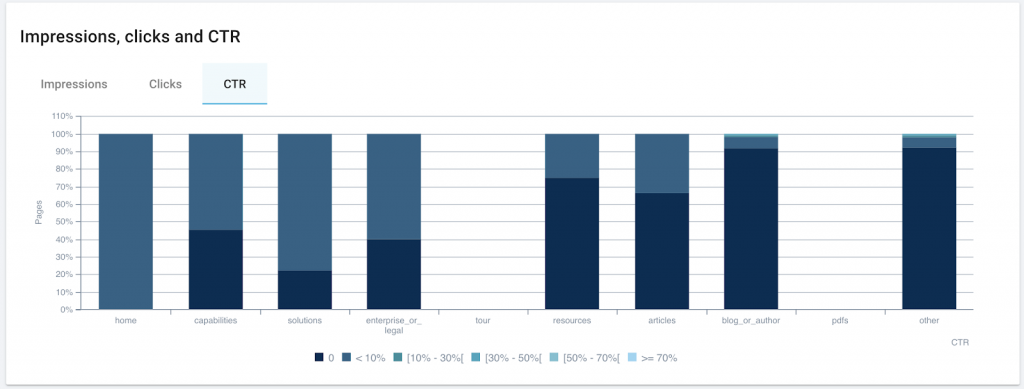
En plus de signaler les problèmes de duplication on-page, comme les titres, descriptions et H1 réutilisés, OnCrawl mesure le niveau de similarité de toutes les pages crawlées. OnCrawl utilise l’algorithme Simhash pour établir la similarité, comme le fait Google.
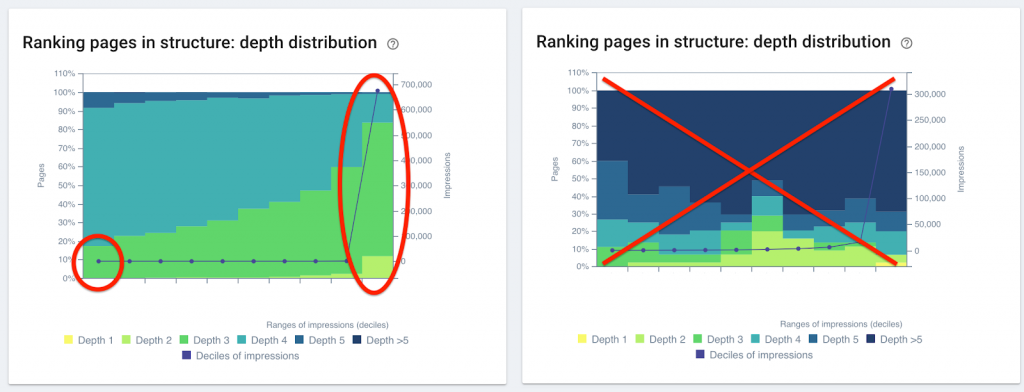
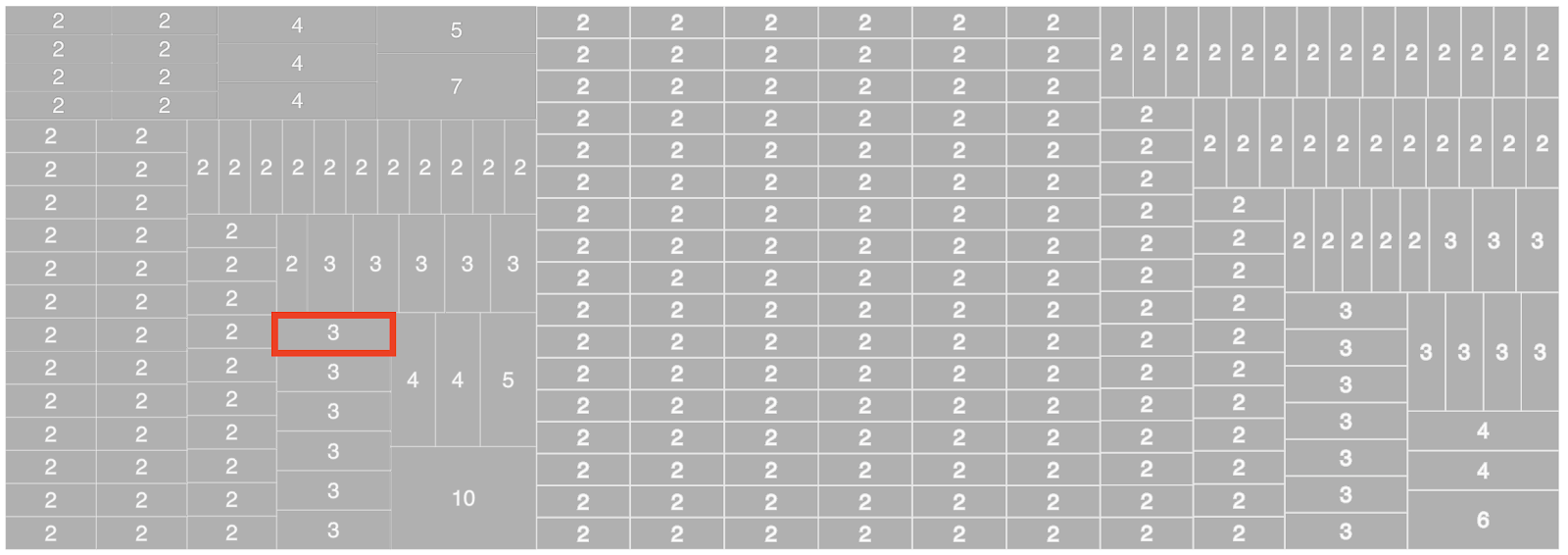
Les pages relativement similaires sont groupées ensemble. Nous appelons ce groupe un cluster de pages avec du contenu dupliqué. Dans un cluster, toutes les pages sont similaires les unes aux autres. Voici une représentation d’un cluster de 3 pages :

Ensuite, OnCrawl regroupe tous les clusters dans un seul graphique. La taille du rectangle est proportionnelle au nombre de pages dans le cluster :
Enfin, OnCrawl fait le lien entre vos clusters et votre utilisation des URLs canoniques. Les déclarations canoniques sont une méthode parmi d’autres permettant d’indiquer à Google que vous avez détecté ce contenu similaire et de lui montrer laquelle des pages similaires est supposée être la version la plus importante.
Chaque cluster est colorié selon l’analyse :
- Vert : toutes les pages du cluster indiquent la même URL canonique.
- Orange : toutes les pages du cluster n’indiquent pas la même URL. Certaines déclarations peuvent manquer, ou quelques pages peuvent indiquer des URLs canoniques différentes des autres.
- Rouge : aucune URL canonique n’est indiquée.
Cette analyse vous permet d’évaluer rapidement le fonctionnement de votre stratégie pour gérer le contenu dupliqué.

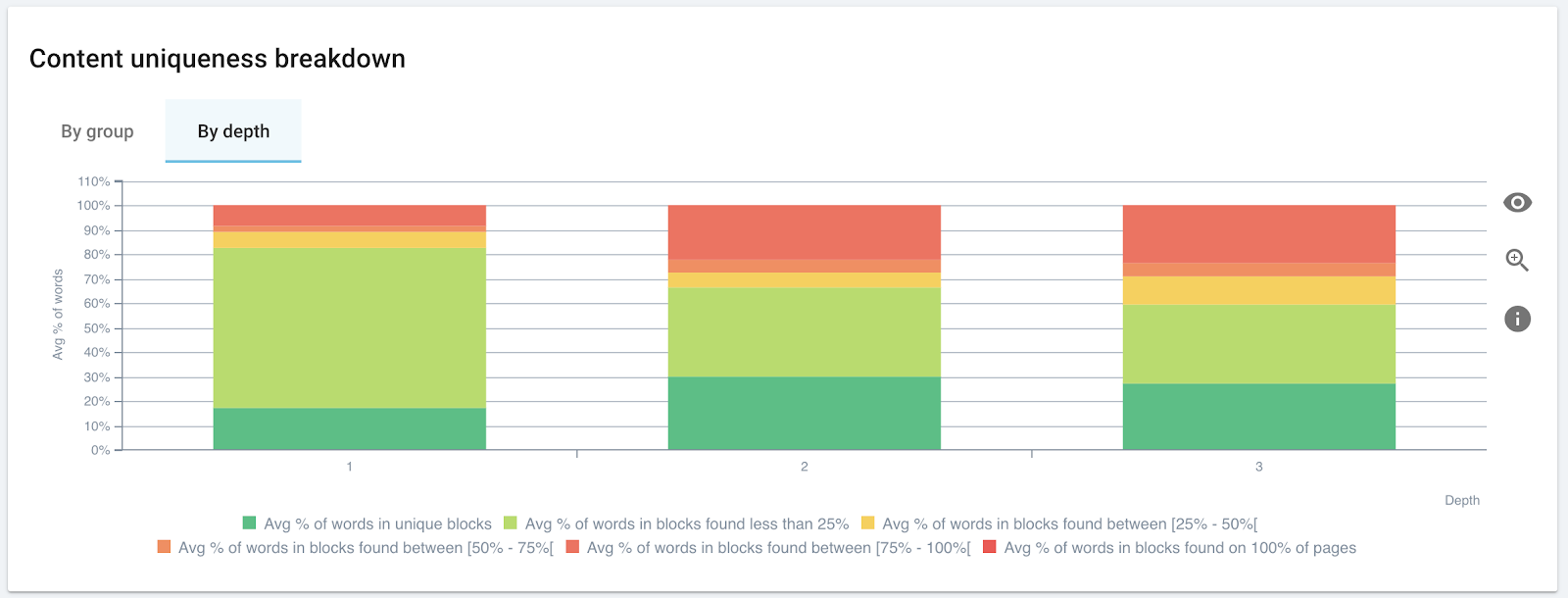
Le slider en haut du graphique vous permet de filtrer pour n’afficher que les clusters d’une taille souhaitée.

Vous pouvez également filtrer par slider les clusters dont la similarité moyenne ne vous concerne pas. Par exemple, vous pouvez prendre en compte uniquement les clusters avec un taux de similarité de plus de 80 %.

Que faire lorsque votre site contient du contenu dupliqué ?
Évaluer votre gestion du contenu dupliqué
La plupart des sites auront besoin d’un mélange des trois stratégies suivantes afin de gérer efficacement leur contenu dupliqué. Voici quelques signes d’une stratégie bien implémentée :
Gestion du contenu dupliqué par la différenciation des pages : le contenu des pages est modifié pour qu’elles ne soient plus similaires.
- Peu de clusters de pages similaires
- Peu de pages par cluster
- Taux de similarité par cluster bas
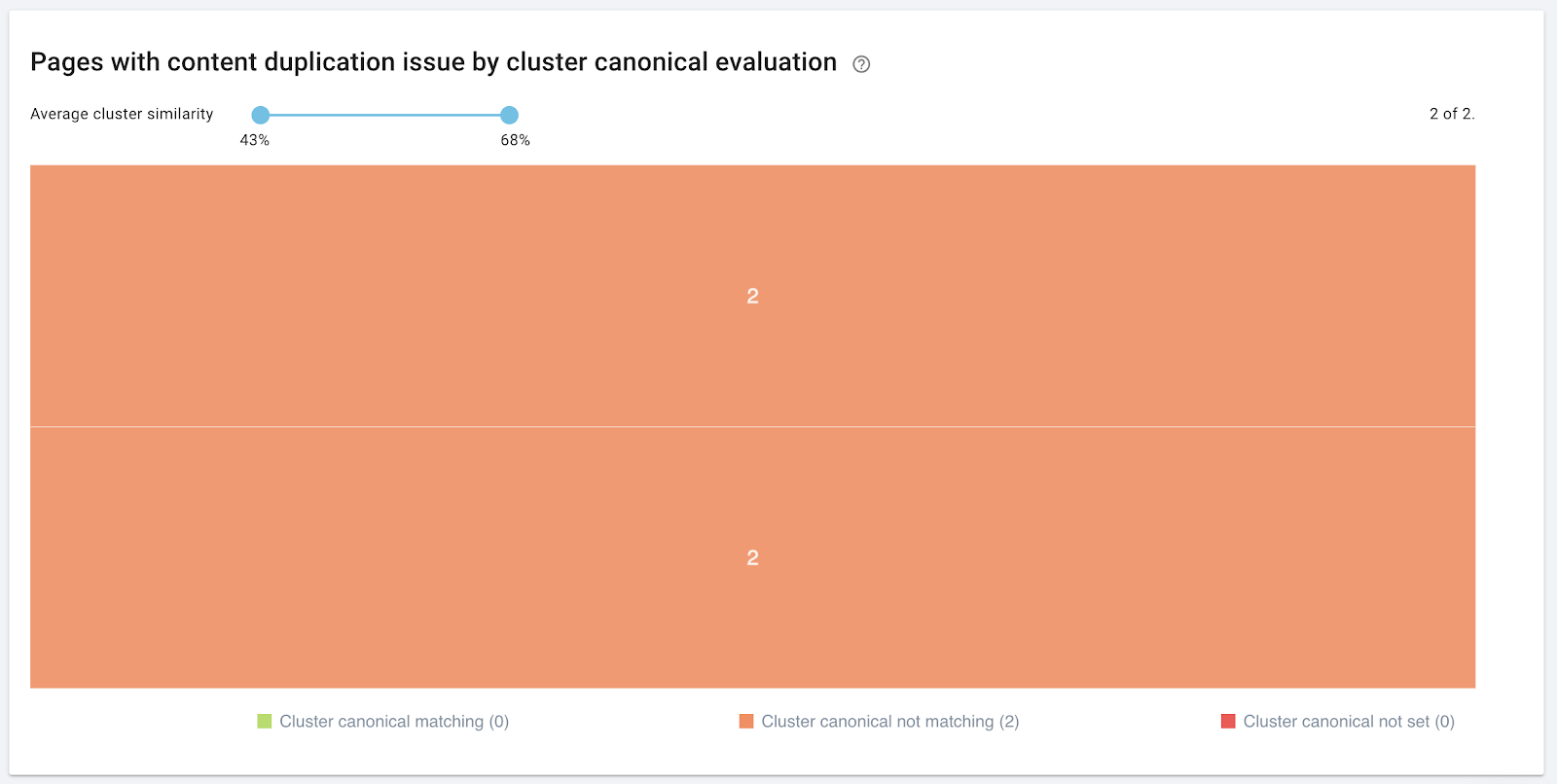
Gestion du contenu dupliqué par déclarations canoniques : une URL canonique est déclarée pour chaque page similaire et seule l’URL canonique est indexée.
- Pas de clusters rouges
- Peu ou pas de clusters oranges
- Les clusters contenant un nombre important de pages sont justifiés
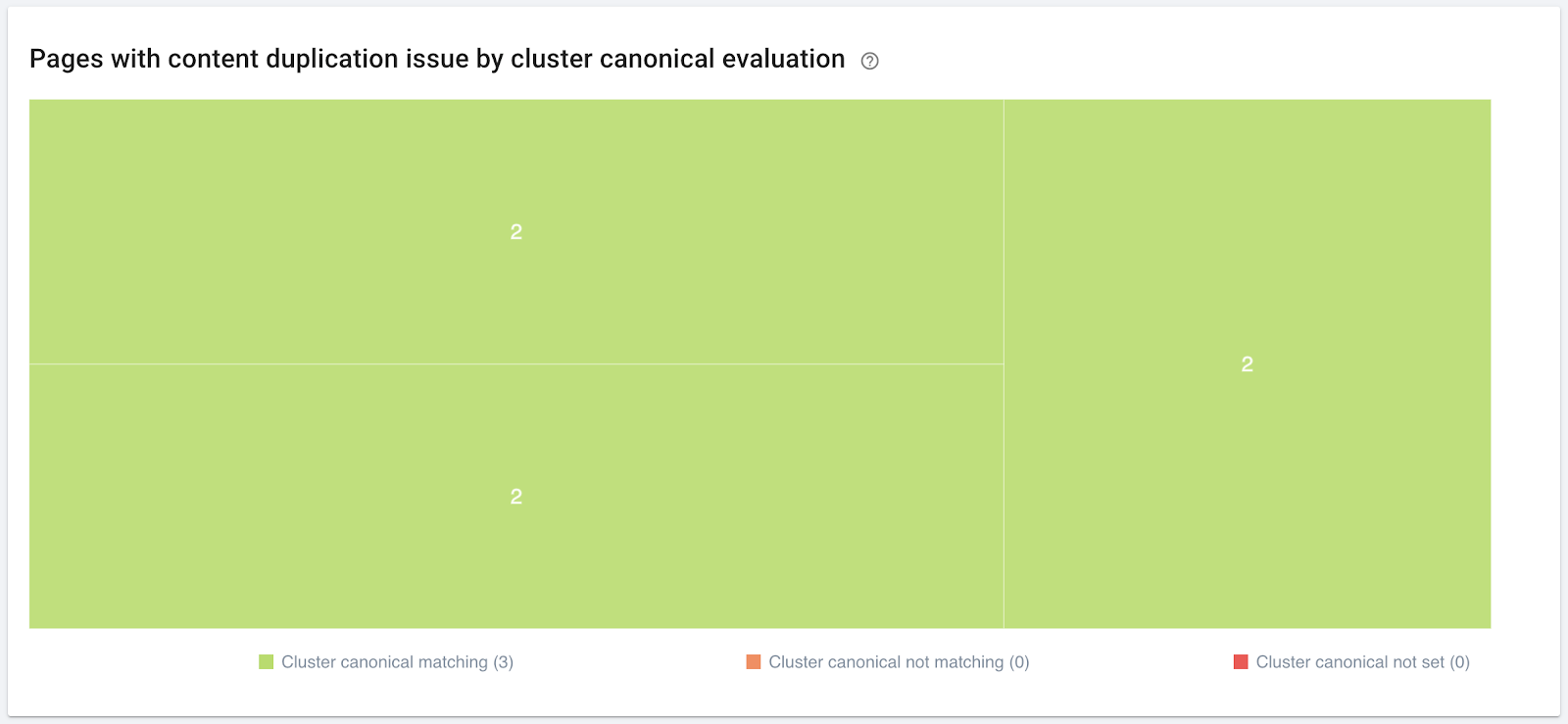
Gestion du contenu dupliqué par la fermeture des pages dupliquées au crawl et à l’indexation : les instructions aux robots, notamment la balise meta robots noindex, sont utilisées pour éviter l’indexation des pages dupliquées.
- Taux de similarité par cluster bas
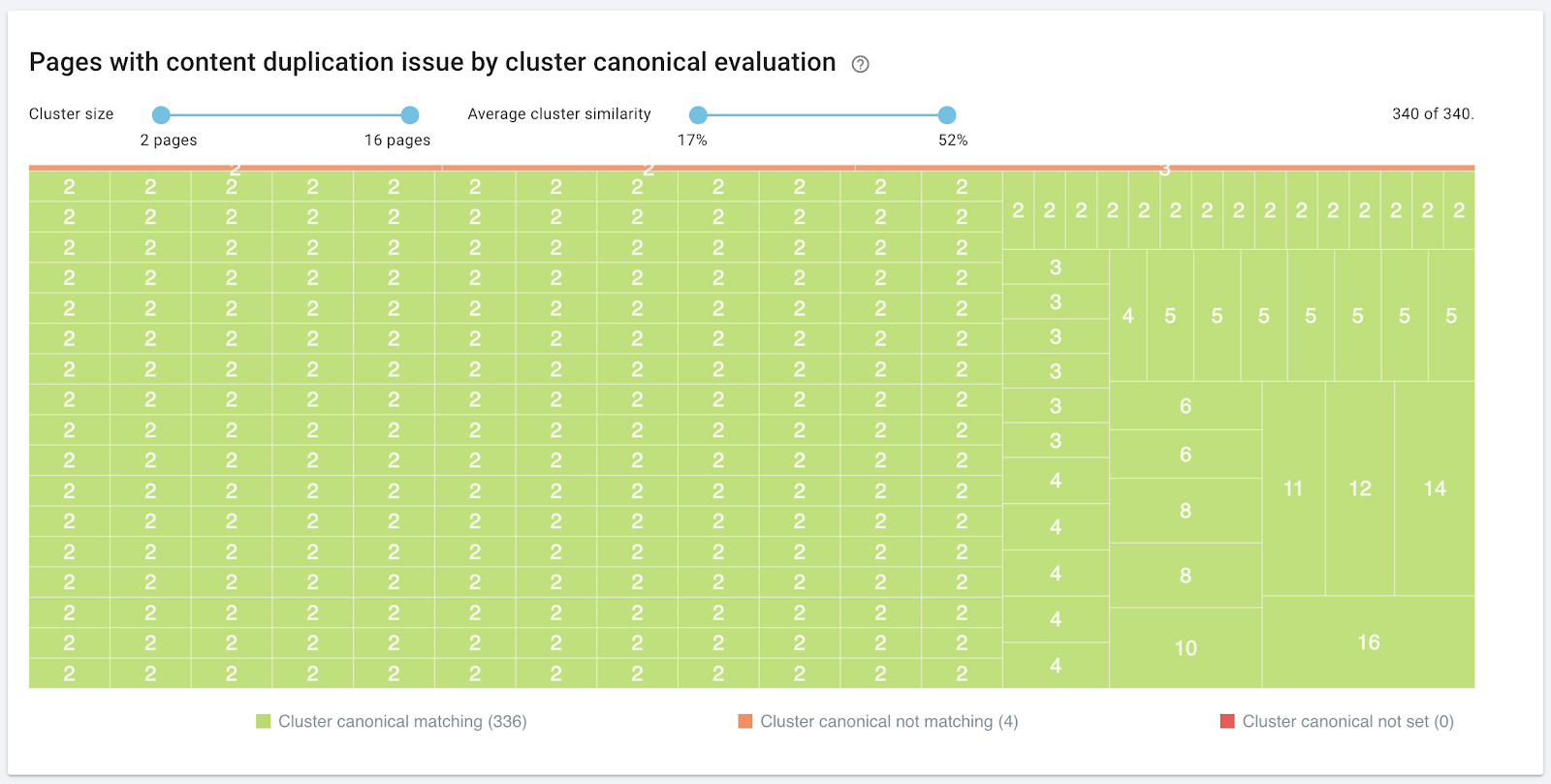
Mise en place d’une nouvelle stratégie ou remaniement de la stratégie actuelle
Si votre stratégie de gestion de contenu dupliqué ne fonctionne pas, voici une façon d’utiliser notre graphique pour trouver le point d’entrée afin de pouvoir la corriger:
- Glissez le slider de taux de similarité pour n’afficher que les clusters avec une similarité d’au moins 80 %.
- Paramétrez la taille du cluster afin qu’il reste gérable pour votre équipe SEO. Si vous ne savez pas quelle taille vous conviendrait le mieux, commencez par des clusters avec un maximum de 4 pages.
- Enlevez les rectangles verts.
- Ne traitez pas les pages une par une, recherchez les tendances cluster par cluster. Posez-vous les questions suivantes :
- Est-ce que tous les clusters que je regarde contiennent une URL mal formée ?
- Est-ce que tous les clusters de cette taille et de ce taux de similarité contiennent une page catégorie ?
- Est-ce que la plupart des clusters que je regarde contiennent un seul type de page ?
- …
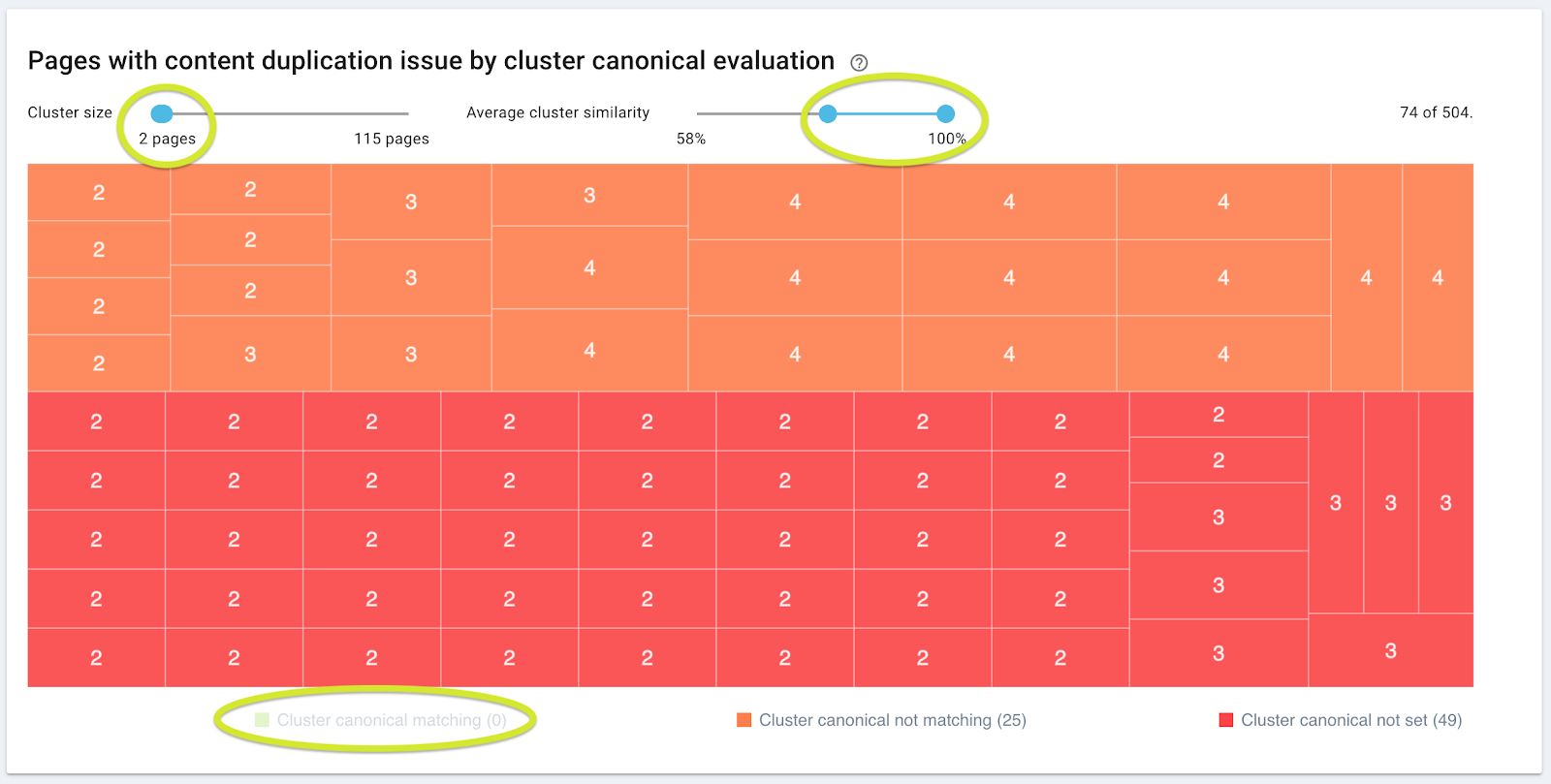
À vous d’affiner votre gestion des pages dupliquées !
Les pages dupliquées constituent l’un des enjeux clés du SEO. Par exemple, les pages trop similaires peuvent se concurrencer pour des recherches identiques, ou bien les pages dupliquées peuvent ne pas être indexées à cause d’une version plus importante que vous (ou, ce qui est de plus en plus commun, Google) auriez indiquée. Vous pouvez éviter ces situations et augmenter les chances que Google accepte vos déclarations canoniques en utilisant des appuis simples.
OnCrawl vous aide à :
- Suivre les groupes de pages qui paraissent similaires sur la base des algorithmes utilisés par Google
- Évaluer l’étendu et l’importance du contenu dupliqué sur votre site, selon le nombre et la taille des clusters
- Se concentrer sur les clusters les plus importants
- Déterminer l’efficacité de votre stratégie de déclarations canoniques en utilisant un code couleur.
Vous n’êtes pas encore utilisateur OnCrawl ? C’est le moment idéal pour commencer votre essai gratuit, acquérir de nouvelles perspectives grâce aux vraies données de votre site web et profiter de l’expertise de nos Customer Success Managers chez OnCrawl.
[Read More ...]