Craignant de voir le coût de ses chantiers exploser de 20 %, la Ville de Québec a reporté 133 des...
[Read More ...]
Tuesday, 31 July 2018
Monday, 30 July 2018
Mise à jour de l’index historique
Nous avons mis à jour l’index historique. Voici les dernières statistiques : URLs crawlées uniques
[Read More ...]
Friday, 27 July 2018
Dérapages autour de bandes cyclables à Limoilou
Au coeur de Québec, le quartier Limoilou, ses triplex et ses places éphémères font mentir ceux qui...
[Read More ...]
[Read More ...]
Les 5 chiffres SEO qui nous ont marqué cette semaine (21/07 au 27/07)
Quels sont les 5 chiffres SEO qui nous ont marqué cette semaine ? L’équipe @OnCrawl vous a préparé son top 5 des chiffres les plus marquants. L’ensemble des données utilisées proviennent de sources anglophones. Google, recherche visuelle, recherche vocale, UX & temps de chargement : découvrez nos 5 actualités SEO de la semaine.
90 % des recherches web ont lieu sur Google
Beaucoup d’apprentis SEOs s’interrogent sur l’importance des moteurs de recherche qui entourent Google. La plupart des gens savent que Google dispose de la plus grande part de marché, mais à quel point est-il important d’optimiser son site par rapport aux pré-requis de Bing, Yahoo et les autres ? La vérité est que malgré l’existence de 30 moteurs de recherche, la communauté SEO ne s’intéresse qu’à Google. En effet, avec près de 90 % des recherches effectuées sur le web, Google représente 20 fois l’activité de Bing et de Yahoo combinés.
Lire l’article
Seulement 8 % des marques ont développé des services de recherche visuelle
L’année dernière, Pinterest et l’application de e-commerce Target ont conclu un partenariat afin que Target puisse utiliser la technologie de recherche visuelle de Pinterest. Une récente étude a montré que seulement 8 % des marques retail avaient développé des services de recherche visuelle répertoriant leurs produits. L’auteur de l’article s’attend à voir ce chiffre augmenter, étant donné que la recherche visuelle a enregistré une croissance de 27 % en 2017.
Lire l’article
La recherche vocale a enregistré 400 % de croissance en Inde
Google a lancé près de 30 nouveaux langages pour son service de recherche vocale l’année dernière et 9 d’entre eux étaient des dialectes indiens. Et pour cause, le marché vocal indien est en pleine expansion ! 28 % de l’ensemble des recherches sont réalisées via la recherche vocale qui a enregistré une croissance de 400 % l’année passée. Un véritable challenge pour Google qui doit composer avec les 22 langues officielles, les 13 écritures différentes et les 720 dialectes du pays.
Lire l’article
94 % des opinions négatives sur un site proviennent du design
L’UX design fait partie des facteurs SEO à optimiser si vous cherchez à augmenter vos classements et vos visites organiques. Une étude a montré que 94 % des opinions négatives sur un site étaient dues à des erreurs de design. Il suffit de 50 millisecondes pour que l’utilisateur se fasse une première opinion de votre site. Il faut donc veiller à proposer une navigation claire et rapide pour orienter au mieux vos visiteurs.
Lire l’article
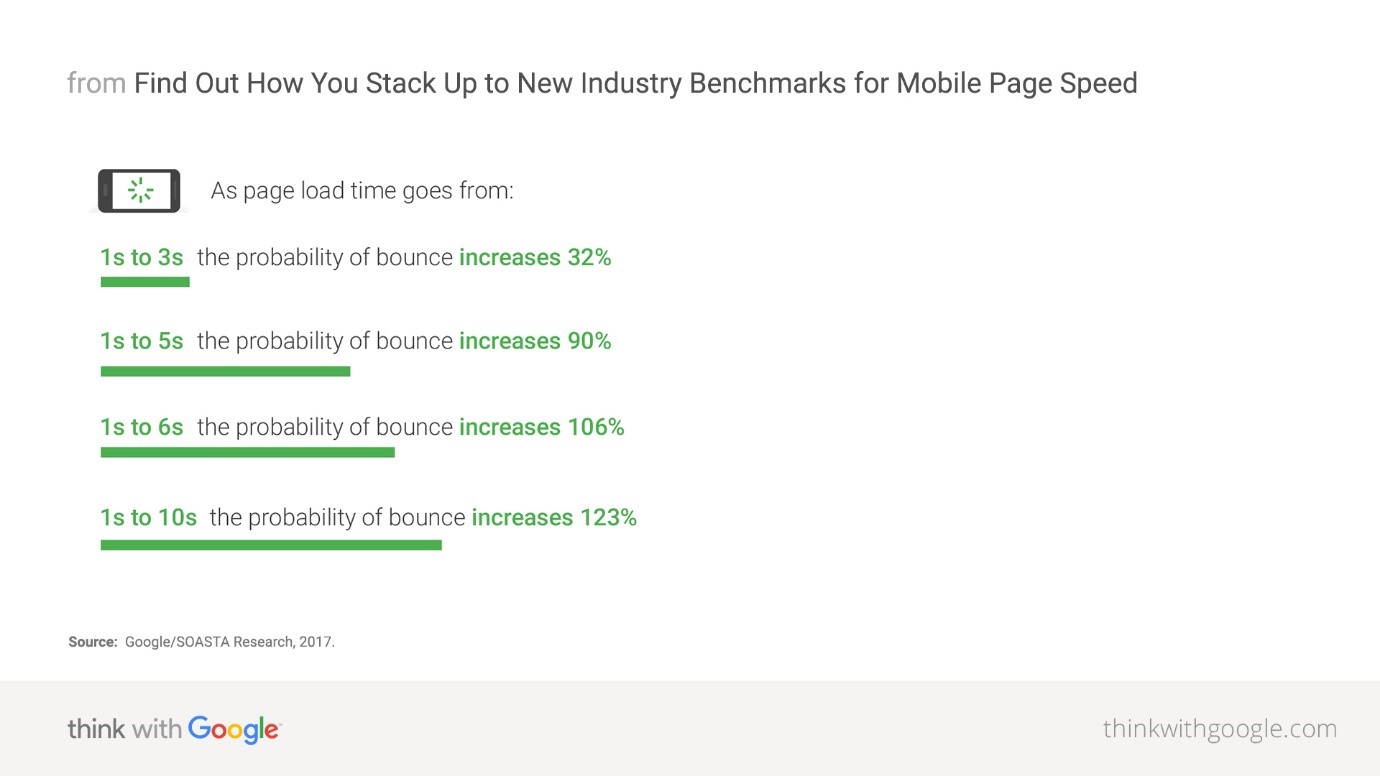
Un temps de chargement supérieur à 5 secondes peut augmenter votre taux de rebond de 90 %
L’expérience utilisateur passe également par un facteur crucial aux yeux de Google : le temps de chargement. Google a d’ailleurs récemment déployé sa mise à jour Speed Update sur mobile qui pénalise les sites web dont le temps de chargement est trop long. D’après les données du moteur de recherche, 3 secondes de chargement augmenterait le taux de rebond de 32 %, 5 secondes de 90 % et 10 secondes de 123 %.
Lire l’article
[Read More ...]
Thursday, 26 July 2018
Maladie hollandaise de l’orme : le combat se poursuit avec de nouvelles pratiques
Québec, le 26 juillet 2018 – La Ville de Québec emploie de nouvelles façons de faire pour lutter plus efficacement contre la propagation de la maladie hollandaise de l’orme. Ces nouvelles pratiques se greffent au Programme de lutte contre la maladie hollandaise de la ville, programme déjà très performant.
Première municipalité à implanter un programme de lutte intégrée contre la maladie hollandaise de l’orme au Canada, la Ville de Québec est encore aujourd’hui une des rares villes à en posséder un pour conserver les ormes sur son territoire. Jusqu’à maintenant, les efforts d’application et d’innovation pour ce programme permettent à la ville de maintenir un taux de mortalité des ormes en deçà de 3 % sur ses terrains, un excellent taux considérant le nombre d’ormes et leur proximité.
Nouvelles pratiques pour le Programme de lutte
De nouvelles façons de faire s’ajoutent au Programme de lutte contre la maladie hollandaise afin d’éviter la propagation cette maladie. Certains ormes ciblés peuvent recevoir un traitement les protégeant contre la maladie, soit l’Arbotect 20-S. Sur les ormes atteints de façon incurable, dans certaines situations, la Ville procède à l’incision de l’écorce et des tissus vivants du tronc de l’arbre sur toute sa circonférence empêchant le déplacement du champignon responsable de la maladie vers les racines (annelage). Elle peut également créer une petite tranchée dans le sol autour des ormes atteints afin d’éviter la propagation par greffe racinaire (cernage). Tout est mis en œuvre dans ce programme pour veiller à conserver les ormes en santé. Cependant, l’abattage demeure souvent la seule solution pour éviter la propagation de la maladie et ainsi, sauver les ormes en santé à proximité.
La Ville invite tout citoyen à s’informer sur les nouvelles pratiques de lutte contre la maladie hollandaise de l’orme en consultant le ville.quebec.qc.ca/MaladiesArbres
Limiter la propagation par l'abattage et la disposition du bois
La maladie hollandaise de l’orme peut affecter les ormes partout sur le territoire et de façon aléatoire. Depuis le début de l’année, deux sites appartenant à la Ville où les ormes d’Amérique occupent une place importante ont été touchés par la maladie. Au cours des prochaines semaines, cinq ormes atteints de la maladie de façon incurable seront abattus et éliminés conformément à la réglementation : quatre sur le boulevard Langelier et un dans le parc Saint-Matthew.
Depuis 1981, le Programme de lutte contre la maladie hollandaise de l’orme de la Ville de Québec est basé sur la détection, l’abattage et l’élimination rapide des arbres atteints afin d’éviter la propagation de la maladie. Le personnel responsable de l’application de ce programme identifie les arbres malades sur l’ensemble du territoire et informe les propriétaires d’ormes sur les façons d’abattre et d’éliminer le bois.
Maladie hollandaise de l’orme
La maladie hollandaise de l’orme s’attaque principalement à l’orme d’Amérique, arbre emblème de la ville de Québec. Les feuilles des branches atteintes de cette maladie se flétrissent, jaunissent, se dessèchent en s’enroulant sur elles-mêmes et finissent par tomber au sol. La maladie est causée par un champignon microscopique transporté principalement par un insecte, le scolyte. Ce champignon se développe dans les vaisseaux conducteurs de la sève l’empêchant de monter jusqu’à la cime.
[Read More ...]
Les mises à jour de l’été 2018 d’OnCrawl : améliorez l’interprétation de vos résultats
Nous sommes très heureux de vous proposer un ensemble de nouvelles améliorations pour rendre l’analyse de vos crawls et l’interprétation des résultats aussi plaisant qu’une journée d’été. Si vous avez été fidèle à votre poste au cours des dernières semaines, vous avez certainement déjà remarqué quelques-uns de ces changements. Si vous n’étiez pas au bureau, nous espérons que vous avez profité de vos vacances ! Voici ce à quoi vous pouvez vous attendre à votre retour.
Nous allons vous présenter les mises à jour produits suivantes :
- Raccourcis des réponses à vos questions pour chaque URL
- Nouvelles fonctionnalités de segmentation automatique
- Nouveau mode de crawl : URL list
- Améliorations bonus
Raccourcis des réponses à vos questions pour chaque URL
Nous avons ajouté un menu de raccourcis de navigation URL dans le Data Explorer et presque partout ailleurs où vous pouvez voir un tableau d’URLs.
À côté de chaque URL dans le tableau de résultats, vous trouverez maintenant une flèche qui ouvre un menu de raccourcis.
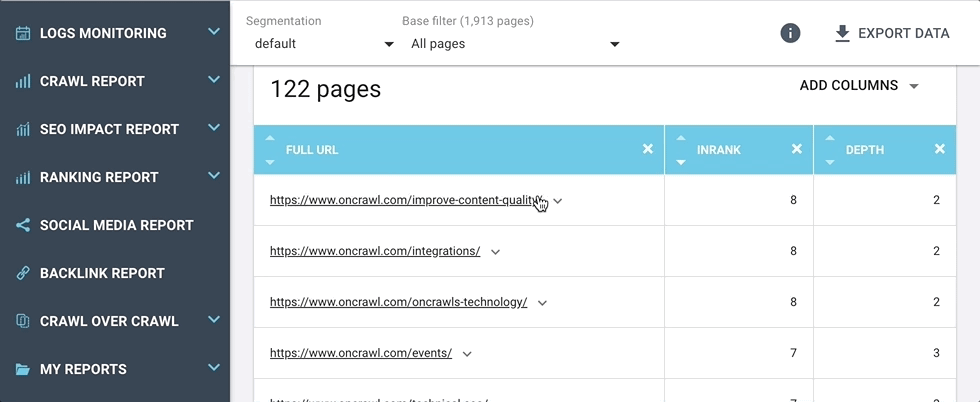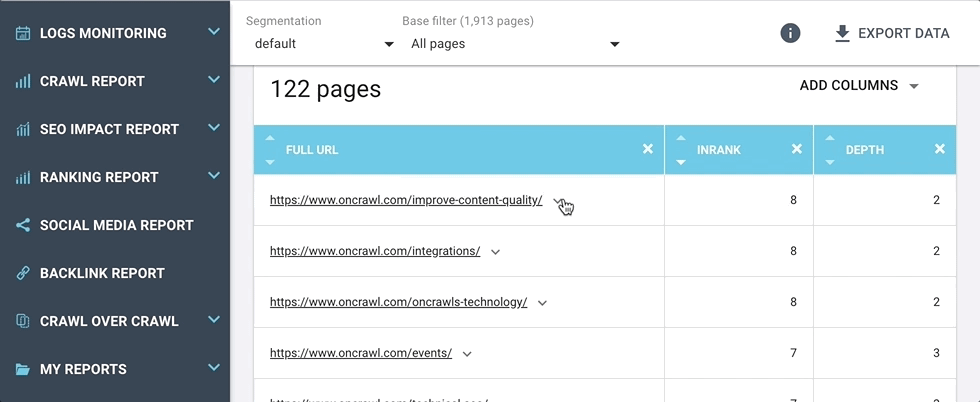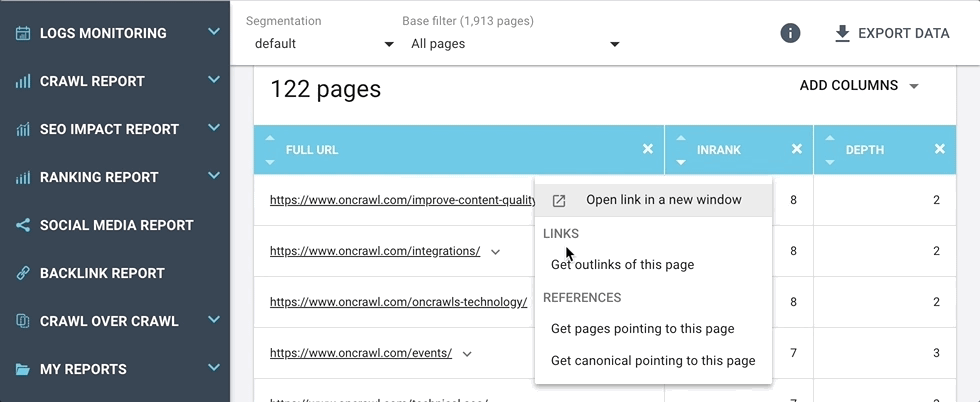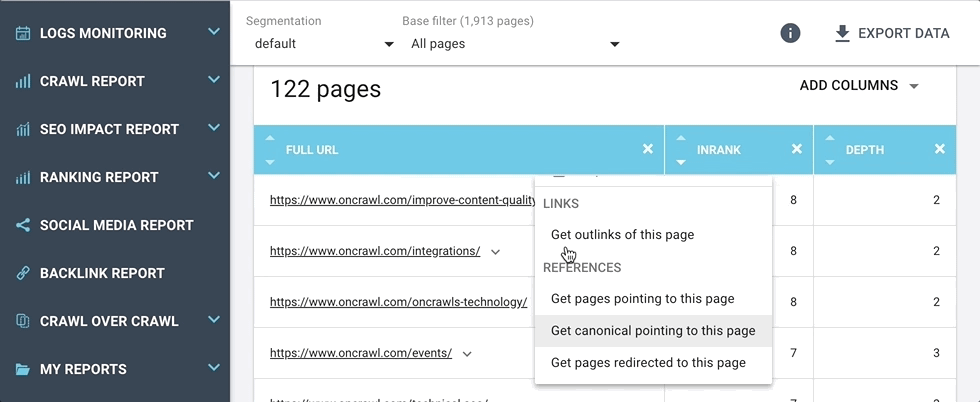
Ces raccourcis vous emmènent directement aux réponses des questions que vous pourriez vous poser à propos de l’URL, par exemple :
- D’où vient cette URL à l’apparence douteuse ?
- Je vois que cette page à des problèmes de duplication pour la description, mais quelles pages ont la même description ?
- Je sais que cette page fait partie d’un groupe pour hreflangs ou de contenu dupliqué, mais quelles sont les autres pages dans le groupe ?
- Si cette page dispose d’une canonique équivalente, c’est super. Mais quelles sont les pages qui répertorient cette URL comme leur page canonique ?
- Je sais qu’un groupe de pages redirige vers cette URL, mais lesquelles sont-elles ?
Ce menu est dynamique, et, selon le contexte, vous pouvez y trouver des raccourcis aux informations suivantes :
- Listes des pages liées (incluant les liens internes, externes, redirections, canoniques, hreflangs) ;
- Listes des pages avec du contenu dupliqué partagé ;
- Listes des événements pour cette page ;
- Listes des passages de bots pour cette page.
Nouvelles fonctionnalités de segmentation automatique
Nous avons étendu les capacités de création des segmentations.
Par défaut, nous vous offrons toujours une segmentation basée sur le premier répertoire (“URL first path”) des URLs crawlées.
Lorsque vous créez une segmentation personnalisée, nous vous offrons désormais une analyse automatique d’un crawl précédent, nous vous proposons une segmentation basée sur des champs personnalisés, ou encore sur l’hôte de l’URL.
Toutes les segmentations sont disponibles pour les logs et les crawls. Cependant, si vous essayez d’utiliser des critères de segmentation qui ne peuvent pas être appliqués aux logs ou aux résultats de crawl, nous vous avertirons immédiatement que votre segmentation ne pourra pas être utilisée pour tous les types de rapports. Si vous avez reçu un avertissement qui indique que votre segmentation ne peut pas être utilisée sur les rapports de résultats de crawl, par exemple, le rapport ne sera pas disponible en tant que choix lorsque vous consulterez les résultats de crawl.
Comment segmenter les résultats de crawl basés sur des champs personnalisés
Pour utiliser un champ personnalisé, vous devez disposer au préalable d’un crawl avec des champs personnalisés. OnCrawl utilisera Nous allons utiliser ces champs pour créer automatiquement une segmentation pour vous. Consultez notre documentation si vous avez besoin d’un coup de pouce lors de la création de champs personnalisés pour un crawl.
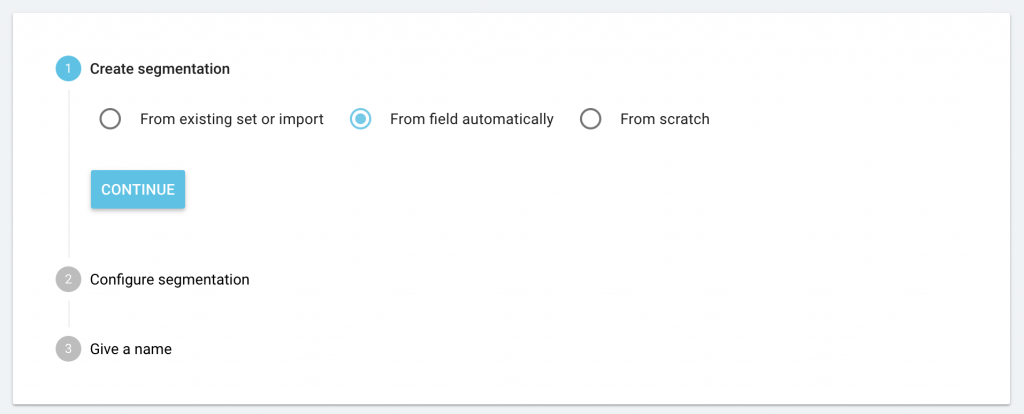
Depuis la page d’accueil du projet, cliquez sur “Manage segmentation”, puis sur “+ Create segmentation”.
Vous verrez apparaître la nouvelle option “From field automatically” ainsi que les options déjà existantes : “From existing or import” et “From scratch”. Choisissez “From field automatically” puis cliquez sur “Continue”.
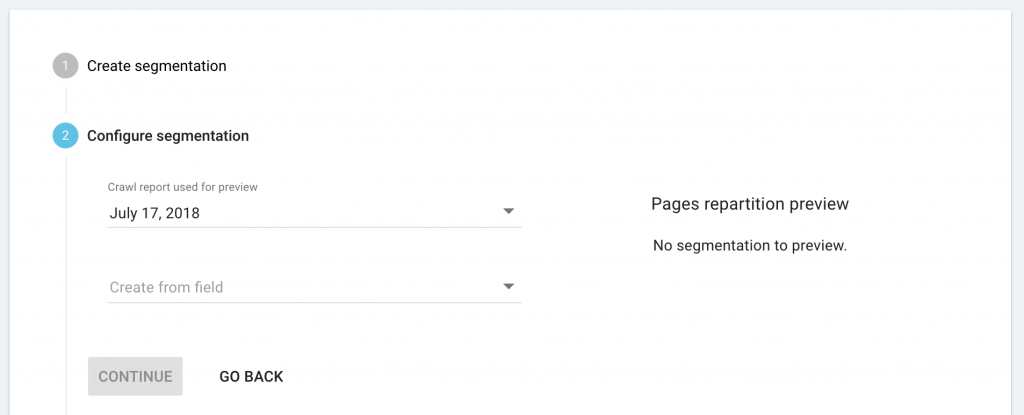
Depuis le menu déroulant, sélectionnez le crawl existant avec les champs personnalisés que vous souhaiteriez utiliser.
Depuis le menu déroulant, sélectionnez les champ personnalisés que vous souhaiteriez utiliser pour créer une segmentation automatique.
Cliquez sur “Continue” afin de renseigner un nom pour la nouvelle segmentation puis enregistrez-la
Votre nouvelle segmentation ne sera certainement pas utilisable pour le monitoring de log, à moins que le champ personnalisé que vous avez choisi soit basé sur l’URL de la page, ou sur d’autres données disponibles dans vos logs.
Comment segmenter vos résultats de crawl basés sur l’hôte de l’URL (lorsque vous crawlez des sous-domaines ou des domaines multiples)
Pour utiliser l’hôte de l’URL afin de générer une segmentation automatique, vous devez avoir déjà conduit un crawl avec des sous-domaines ou un crawl avec des domaines multiples.
Depuis la page d’accueil du projet, cliquez sur “Manage segmentation”, puis sur “+ Create segmentation”.
Vous verrez la nouvelle option “From field automatically” ainsi que les options déjà existantes : “From existing or import” et “From scratch”. Choisissez “From field automatically” puis cliquez sur “Continue”.
Depuis le menu déroulant, sélectionnez les crawls existants avec les domaines multiples ou les sous-domaines que vous souhaitez utiliser.
Depuis le menu déroulant, sélectionnez le champ “URL host”.
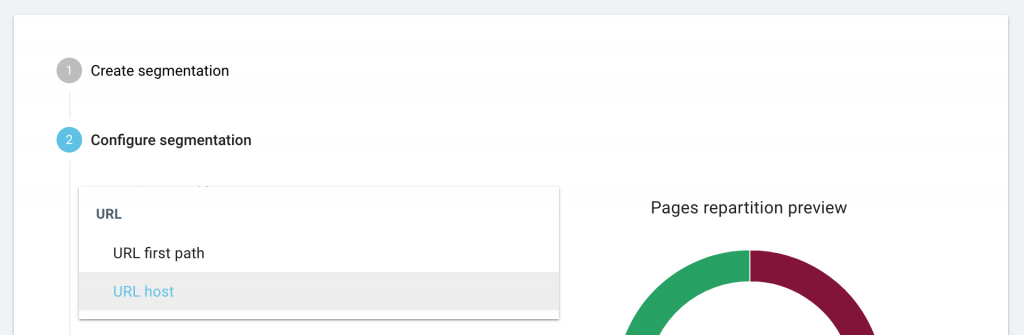
Cliquez sur “Continue” pour renseigner un nom pour la nouvelle segmentation et sauvegardez là.
Cette segmentation est basée sur l’URL et peut ainsi s’appliquer à tous vos rapports.
Nouveau mode de crawl : URL list
Vous nous l’avez demandé, nous l’avons fait. Vous pouvez désormais crawler une liste d’URLs.
Comment crawler une liste d’URLs ?
Lorsque vous configurez un crawl, vous pouvez maintenant décider si vous préférez crawler le site avec un crawler standard qui explore la structure en suivant les liens de chaque page qu’il visite, ou bien crawler une liste statique d’URLs.
Lorsque vous crawlez une liste d’URLs, le crawler va visiter chaque page de la liste que vous fournissez, mais ne va suivre aucun des liens. Cette fonctionnalité limite le crawl aux URLs dans la liste.
Dans les paramètres de crawl, sélectionnez “URL mode” puis téléchargez une liste d’URLs. Vous pouvez également sélectionner une liste d’URLs que vous avez précédemment téléchargée. Lorsque vous lancez un crawl, seules les URLs dans la liste seront crawlées.
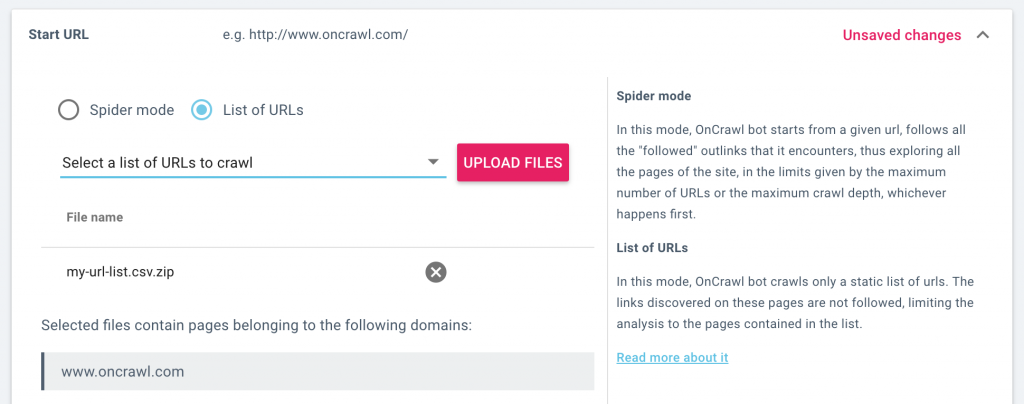
Vous pouvez consulter, gérer et télécharger vos listes d’URL dans la page Data sources. Depuis la page d’accueil du projet, cliquez sur “Add data sources” puis sur “URL lists”.
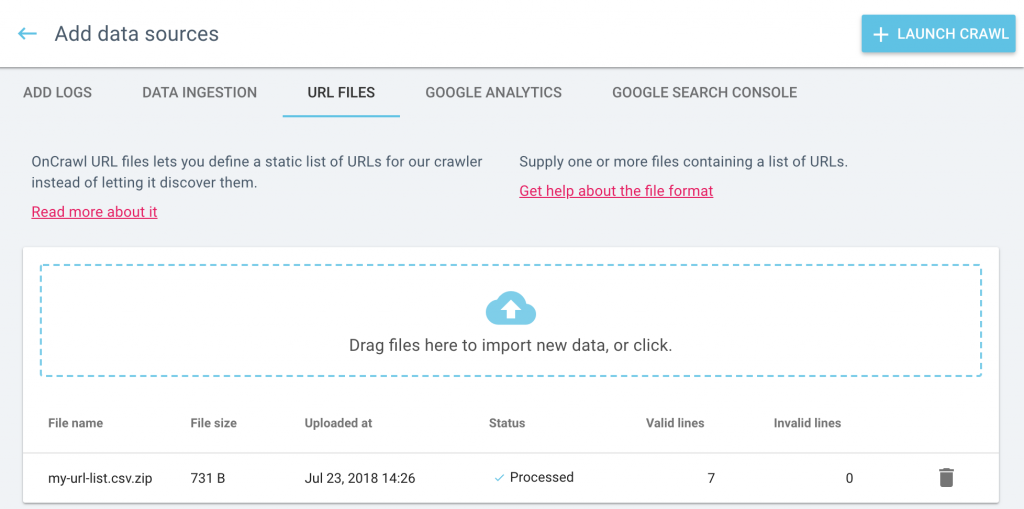
Consultez notre documentation pour plus de détails sur les différences entre le crawl en mode spider et en mode URL list.
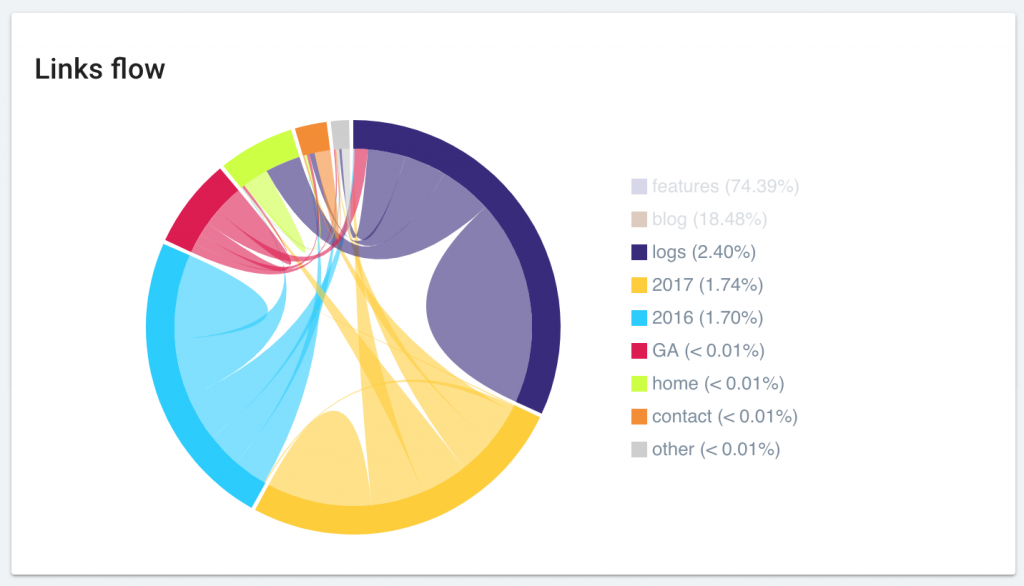
Améliorations bonus
Optimisation du diagramme Link Flow
Nous avons amélioré l’affichage du diagramme “Link Flow”. Votre graphique favoris est maintenant plus beau que jamais et plus simple à interpréter.
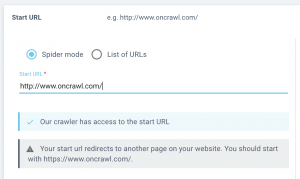
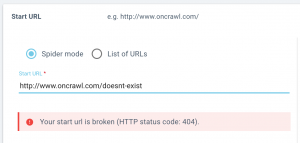
Plus d’accompagnement lors du paramétrage de la start URL
Nous vous ferons savoir si les pages start que vous avez listées peuvent être atteintes par notre crawler, ou s’il est redirigé.
Lorsque vous configurez un crawl, vous saurez immédiatement si le crawl sera en mesure de passer votre start URL. Si nous rencontrons un problème, nous vous ferons savoir si :
- Votre start URL ne peut pas être atteinte (renvoie une erreur 4xx ou 5xx)
- Votre start URL est redirigée (renvoie un status code 3xx)
- Votre start URL ne peut pas être crawlée (les robots sont interdits par les robots.txt)
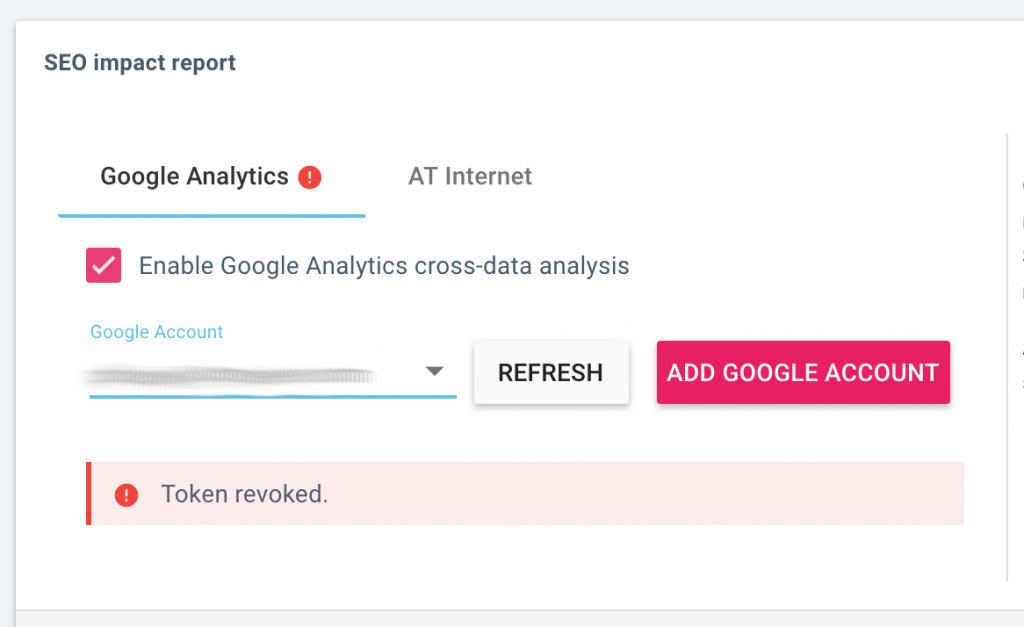
Plus d’accompagnement lors de la connexion d’un service tiers
Lorsque vous configurez un nouveau crawl, nous vous faisons maintenant immédiatement savoir si la connexion à un service tiers a été réussie, ou si nous avons rencontré un problème.
Cela s’applique aux paramètres de crawl dans les sections suivantes :
- Rapport d’impact SEO : connexion à Google Analytics ou AT Internet
- Rapport de classement : connexion à la Google Search Console
- Rapport de backlink : connexion à Majestic
Retrouvez toutes vos données externes et intégrations au même endroit
Nous avons renommé le bouton “Add integrations” en “Add data sources”.
Lorsque vous cliquez sur le bouton “Add data sources”, vous pouvez naviguer à travers les différentes sources en cliquant sur les onglets en haut de l’écran.
Vos données externes et tierces peuvent être ajoutées ici :
- Fichiers de log utilisés pour le monitoring de log, rapports de visites SEO et analyse du budget de crawl ;
- Fichiers du Data ingestion, utilisés pour ajouter des champs personnalisés à l’analyse de chaque URL ;
- Fichiers d’URL, utilisés pour crawler une liste d’URLs ;
- Comptes Google Analytics, utilisés pour les rapports de visites SEO et le comportement du googlebot ;
- Google Search Console, utilisée pour les rapports de classement et les information de mots-clés.
Il s’agit d’un emplacement “tout-en-un” où tout est facile à trouver.
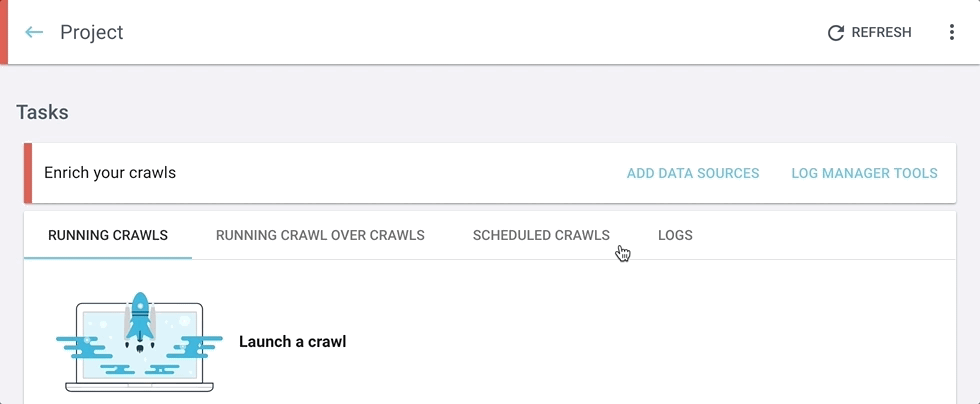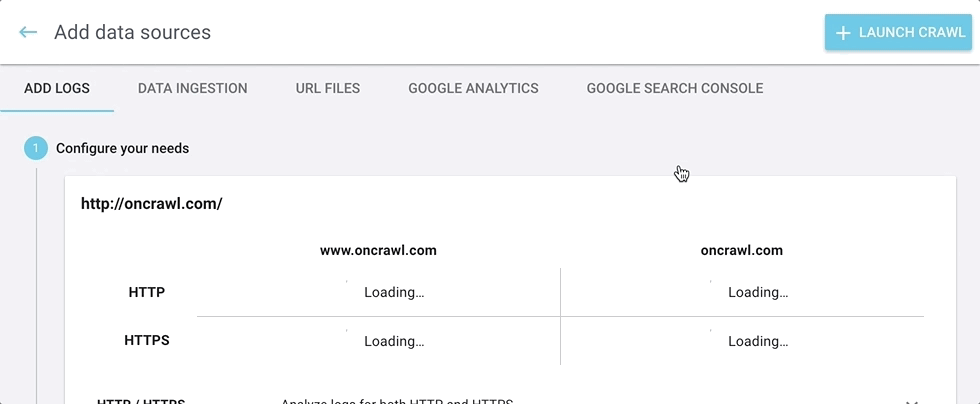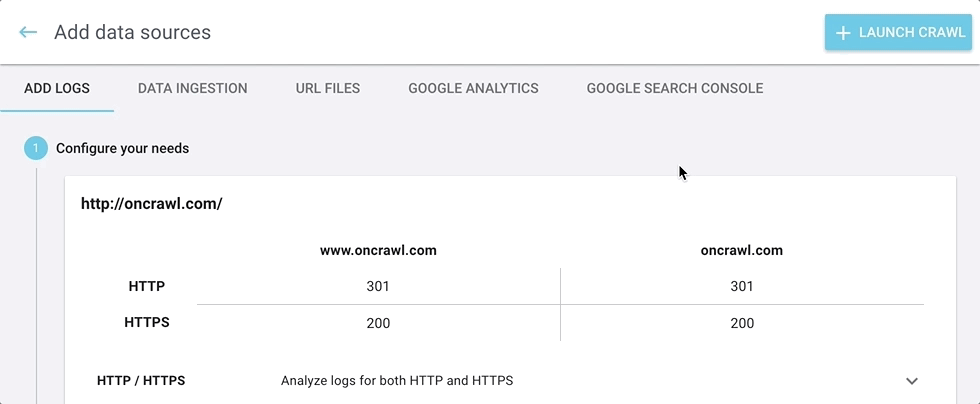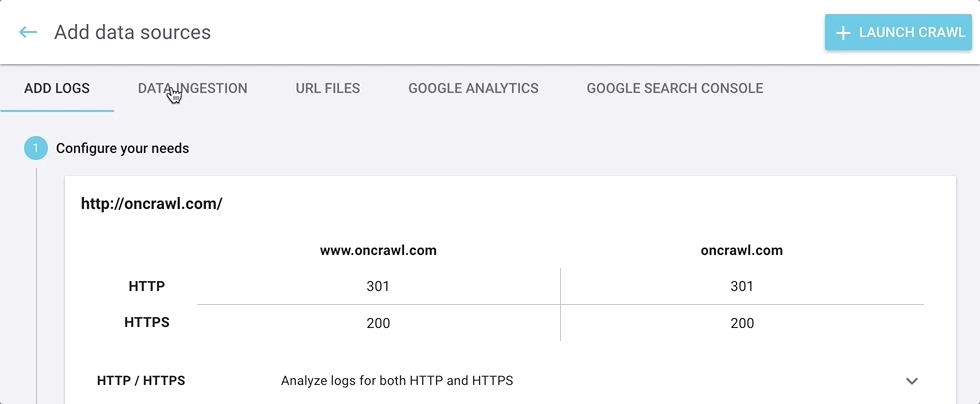
Vous pouvez toujours trouver l’outil de gestion de log à son emplacement habituel, à droite de l’onglet “Enrich your crawls” sous “Tasks” sur la page d’accueil de votre projet.
Tirez le maximum de vos crawls
Si vous n’êtes pas déjà utilisateur OnCrawl, c’est le moment idéal pour faire un essai. Nous offrons une période d’essai gratuite de 14 jours.
[Read More ...]
Thursday, 12 July 2018
7 manières pour les PME d’utiliser Majestic pour le Content Marketing
Majestic est un puissant outil SEO, mais ce n’est pas seulement un vérificateur de backlink
[Read More ...]
Wednesday, 11 July 2018
La finale de la Coupe du monde de la FIFA présentée au Festival d’été de Québec
Québec, le 12 juillet 2018 – La Ville de Québec et le Festival d’été de Québec (FEQ) annoncent que la finale de la Coupe du monde de la FIFA, opposant la France à la Croatie, sera présentée au Cœur du FEQ, à la place de l’Assemblée-Nationale, dès 11 h le dimanche 15 juillet. Cette diffusion est rendue possible grâce à l’initiative du Consulat général de France à Québec.
Les partisans pourront y encourager leur équipe favorite alors que la joute sera présentée sur écran géant. Les visiteurs auront également accès à l’offre alimentaire variée habituelle du Cœur du FEQ, qui ouvrira une heure plus tôt pour l’occasion. L’accès, gratuit, est limité à 2 500 personnes. À noter que comme le Festival d’été bat toujours son plein, le son de la diffusion de la joute sera momentanément interrompu à deux ou trois reprises en raison de tests de son. L’Interruption devrait durer une dizaine de minutes tout au plus.
La ville en mode festival
Rappelons que le 51e Festival d’été de Québec bat son plein jusqu’au dimanche 15 juillet. Il s’agit de l’évènement musical extérieur le plus important au Canada, en plein cœur de la ville de Québec. Le FEQ anime la ville entière pendant 11 jours et dans 10 lieux urbains différents et uniques. Les têtes d’affiche à venir d’ici le 15 juillet sont : les Chainsmokers, Beck, Cyndi Lauper, Lorde, Avenged Sevenfold, Sturgill Simpson et Dave Matthews Band.
Pour tout savoir, consultez le infofestival.com.
Un été animé à Québec
La saison estivale est particulièrement festive à Québec, avec la présentation notamment des Passages Insolites, du spectacle de cirque Féria par FLIP Fabrique, des Grands feux Loto-Québec, du Grand Prix cycliste, du Festival de cinéma de la ville de Québec, du Marathon SSQ de Québec et de nombreux autres événements culturels et sportifs.
[Read More ...]
Comment Google évalue l’utilisabilité d’un site ? 4 facteurs clés
Il y a bien longtemps que la raison d’être et l’aboutissement du SEO n’est plus le link building. Depuis au moins 2011, (avec la mise à jour Panda), Google a utilisé des métriques permettant de mesurer l’utilisabilité d’un site web, en plus des liens entrants en tant que facteur de classement.
Soit disant passant, prenez garde à ne pas confondre les termes “utilisabilité” et “expérience utilisateur”. Les marketers utilisent souvent ces deux termes indistinctement mais ils ne devraient pas. Wordtracker explique très bien la différence entre les deux concepts, mais concrètement, l’utilisabilité renvoie à la facilité d’utilisation d’un site web et l’expérience utilisateur à la manière dont l’utilisateur se sent lorsqu’il interagit sur votre site, en prenant en compte des facteurs comme le branding, la perception de l’utilisateur et ses émotions.
Cet article se concentre sur 4 métriques d’utilisabilité couramment discutées : le taux de rebond, le dwell time, la vitesse d’une page et le nombre de mots.

Le taux de rebond
Brian O’Connell, fondateur & CEO de Asterion SEO a affirmé que le taux de rebond était la métrique d’utilisabilité la plus importante pour le classement d’un site aux yeux de Google. Et cela a du sens jusqu’à un certain point. Si un utilisateur réalise une recherche Google et passe très peu de temps sur le résultat sur lequel il a cliqué, cela pourrait indiquer que le résultat n’était pas suffisamment utile pour la recherche de l’utilisateur.
Mais le taux de rebond ne constitue pas l’intégralité des facteurs de classement. Si un utilisateur est simplement à la recherche du numéro de téléphone de la pizzeria locale ou d’un docteur, et réalise sa recherche dans Google, puis clique sur la page web des résultats de recherche et trouve le numéro directement sur la page d’accueil avant de la fermer. Il s’agit d’une excellente utilisabilité mais est-ce que le site devrait être pénalisé à cause d’un taux de rebond très élevé ? Il est clair que non.
Donc, comment Google résout cela ?
Car Google peut tracker les personnes qui utilisent le navigateur Chrome (et qui ont opté pour), et résoudre le scénario ci-dessus en utilisant une autre métrique appelée “dwell time”.
Dwell Time
Le Dwell time est similaire au taux de rebond mais avec une étape supplémentaire : il mesure combien de temps la personne reste sur un site web après avoir cliqué sur un résultat de recherche puis prend en considération si cet utilisateur retourne aux résultats de recherche pour trouver une autre option. Comme son nom le décrit, cette métrique mesure combien de temps un utilisateur demeure (“Dwell” en anglais) sur un résultat spécifique et s’il décide ensuite de consulter un autre résultat depuis la même recherche. Nous pouvons déduire qu’un dwell time plus long pourrait suggérer un résultat plus pertinent pour Google et qu’un dwell plus court, pourrait laisser penser au contraire. Rappelez-vous, un dwell time n’est valable que si l’utilisateur retourne à la recherche originale pour cliquer sur un autre résultat.
Nous pouvons voir à quel point le dwell time diffère du taux de rebond et comment il résout le scénario “Je n’ai besoin que d’un numéro de téléphone” vu ci-dessus. Si un utilisateur clique sur un résultat de recherche et ne retourne pas sur la page Google pour vérifier les autres résultats, alors un “no dwelling” va apparaître et Google pourrait toujours classer cette page dans les premiers résultats, même si son taux de rebond est élevé et que le temps passé sur la page est faible.
Vitesse d’une page
Depuis au moins 2010, il est connu que Google récompense les sites les plus rapides avec des classements plus hauts. Google dispose même de son propre système très accessible pour mesurer et améliorer la vitesse d’un site web (Google Page Speed insights). Il est toujours pertinent de parier sur le fait que la vitesse est quelque chose d’important pour Google. Mais cela a été confirmé seulement récemment, en avril 2018, lorsque Google a annoncé qu’il utilisait des données réelles des utilisateurs de Chrome pour voir à quelle vitesse une page se chargeait (à l’opposé de conduire des tests logiciels), un nouvel indicateur de l’importance de la vitesse d’une page pour Google.
Cependant, une étude très complète de milliers de termes de recherche et de sites web dirigée par MOZ montre que la vitesse de l’infrastructure backend d’un site est la seule partie importante de l’équation vitesse/classement et que le temps de chargement du front end (la vitesse à laquelle le site se charge pour les utilisateurs) n’avait absolument aucun effet sur les classements. Donc, l’élément clé de cette enquête est d’améliorer aussi bien le temps de chargement du front end que l’hébergement de votre site.
Malgré tous les débats à propos des parties les plus importantes de l’équation vitesse/classements, étant donné qu’un site qui se charge rapidement est visiblement bénéfique pour l’utilisabilité, il n’est pas stupide de tout faire pour améliorer la vitesse d’un site, autant pour le front que pour le back end.
Nombre de mots
Peut-être que le sujet le plus controversé au sujet de l’utilisabilité et de Google est le nombre de mots qu’une page devrait contenir pour mieux se classer. La liste ci-dessous illustre certaines des différences sur ce sujet.
- Forbes suggère que le nombre de mots doit être de 600/700.
- HubSpost a trouvé que les articles les plus performants comptent 2 250 à 2 500 mots.
- Whiteboard Marketing recommande un minimum de 300 mots.
- Backlinko a analysé 1 million de résultats de recherche Google et a trouvé que la moyenne de la première page Google contient 1 890 mots.
MOZ a aussi analysé 1 million d’articles et a trouvé que près de 85 % d’entre eux n’attiraient pas de partages sur les réseaux sociaux et de liens entrants. Les contenus partagés ou liés contenaient eux en moyenne 1000 mots.
Cependant, ces études doivent être considérées avec précaution. Rand Fishkin de Moz compare ces études à “de gros bobards” et pense qu’elles sont trop simples pour rendre des jugements actionnables et ne prennent pas en compte le type de mots-clés, le trafic ou les secteurs analysés. De plus, n’importe qui avec ne serait ce que des connaissances élémentaires sur les statistiques connait les marges d’erreur moyennes. Par exemple, un article qui compte en moyenne 2 000 mots peut en faite être calculé depuis une série de 20 articles contenant chacun 200 mots et d’un article avec 38 000 mots, ce qui donne une moyenne qui ne représente pas réellement la nature de la série.
Le jury se demande toujours si Google s’intéresse réellement au nombre de mots, une meilleure suggestion serait de prendre en considération d’autres facteurs, par exemple si votre contenu génère des liens entrants, dispose d’un faible taux de rebond, dwell time…
[Read More ...]
Tuesday, 10 July 2018
Parc de la Rivière-Beauport : sentier pédestre fermé pendant les travaux
Des travaux de réfection dans le sentier pédestre du parc de la Rivière-Beauport sont en cours, et ce, jusqu’à la fin août. Pendant les travaux, la circulation sur le sentier sera limitée voire entravée à certains endroits. Une signalisation appropriée sera installée pour informer les usagers et sécuriser les lieux.
Le sentier pédestre entre la rue Clemenceau et l’avenue Joseph-Giffard sera restauré : nouvelle surface de marche, remplacement des garde-corps, remplacement des escaliers.
D’autres travaux seront également réalisés dans le secteur du parc Montpellier pour relier les portions de sentier aménagées l’an dernier.
Ces travaux seront réalisés par la Ville de Québec.
[Read More ...]
Le sentier pédestre entre la rue Clemenceau et l’avenue Joseph-Giffard sera restauré : nouvelle surface de marche, remplacement des garde-corps, remplacement des escaliers.
D’autres travaux seront également réalisés dans le secteur du parc Montpellier pour relier les portions de sentier aménagées l’an dernier.
Ces travaux seront réalisés par la Ville de Québec.
[Read More ...]
Friday, 6 July 2018
Fermeture temporaire d'une portion du parc linéaire de la Rivière-Saint-Charles
La Ville de Québec informe les utilisateurs du parc linéaire de la Rivière-Saint-Charles que le sentier pédestre et la piste cyclable (corridor de la Rivière-Saint-Charles) compris entre les ponts Scott et Samson seront fermés le dimanche 8 juillet, entre 6 h et 13 h, en raison de la tenue de l’activité Défi-Entreprises.
Les secteurs de l’embouchure, de l’Anse-à-Cartier, des îlots ainsi qu’une partie du secteur du pont de l’Aqueduc seront donc inaccessibles durant cette courte période. Le but de cette fermeture temporaire est d’assurer la sécurité des marcheurs et des cyclistes empruntant les sentiers de ces installations et aussi celle des participants. Elle vise également à assurer le bon déroulement de l’événement afin qu’il puisse conserver son caractère familial et festif.
Mentionnons que plus de 8 000 participants sont attendus ce 8 juillet au Défi-Entreprises à Québec.
[Read More ...]
Les 5 chiffres SEO qui nous ont marqué cette semaine (01/07 au 06/07)
Quels sont les 5 chiffres SEO qui nous ont marqué cette semaine ? L’équipe @OnCrawl vous a préparé son top 5 des chiffres les plus marquants. L’ensemble des données utilisées proviennent de sources anglophones. Conversions, sites piratés, recherche vocale, blog et cross-device : découvrez nos 5 actualités SEO de la semaine.
81 % des entreprises obtiennent toujours des conversions sur desktop
Cet article résume la conférence d’Alexis Sanders (Merkle) sur le Mobile-First et l’AMP lors de SMX Advanced. Au cours de cette intervention, elle a mis en avant que de plus en plus d’internautes utilisent leur mobile et que Google s’adapte à cette tendance. Le problème, c’est que le mobile est très différent du desktop et qu’il contient des challenges et notamment un écran plus petit, un problème de rapidité, un trafic éclaté entre navigateurs et applications… Face à ces challenges, le desktop n’est pas en perdition et 81 % des entreprises confient d’ailleurs qu’elles font encore des conversions sur ce support.
Lire l’article
Le nombre de sites piratés a augmenté de 32 % entre 2016 et 2015 d’après Google
D’après Google, le nombre de sites piratés a bondi de 32 % entre 2015 et 2016. Heureusement, en 2017, le moteur de recherche a supprimé près de 80 % des sites piratés qu’il a détecté dans ses classements. Même si Google réalise d’importants progrès dans la lutte contre le piratage, il reste très important pour les webmasters de sécuriser au mieux leur site.
Lire l’article
30 % à 50 % de l’ensemble des recherches seront faites via la recherche vocale d’ici à 2020
Êtes-vous prêts pour le futur de la recherche vocale ? Que ce soit via les assistants vocaux ou les smartphones, l’usage de la recherche vocale évolue de plus en plus rapidement. Ainsi, des recherches ont montré que les recherches vocales représenteraient entre 30 % et 50 % de l’ensemble des requêtes d’ici à 2020. Les utilisateurs mobile font de plus en plus appel à cette fonction qu’ils jugent pratique. Place aux stratégies de VEO : Voice Engine Optimization !
Lire l’article
Les sites web qui disposent d’un blog ont 434 % plus de chances d’avoir des pages indexées
Cet article propose 7 conseils basiques pour optimiser le SEO des blogs. Une étude a montré que les sites web qui disposaient d’un blog ont 434 % plus de chances d’avoir des pages indexées. Elles ont également 67 % plus de leads que les autres entreprises. Attention cependant, l’auteur rappelle qu’il ne suffit pas juste d’alimenter un blog avec des contenus. Il est important d’optimiser les pages du blog pour qu’elles se classent dans les moteurs de recherche.
Lire l’article
60 % des internautes avouent régulièrement commencer une recherche sur mobile avant de la finir sur desktop
L’auteur de cet article dénonce une erreur souvent commise : les audiences sur mobile et desktop ne sont pas différentes. Il s’agit des mêmes utilisateurs qui pratiquent le “cross-device”, c’est-à-dire qu’ils jonglent entre leurs différents appareils (smartphone, tv, desktop…). Ainsi, d’après l’étude Multiscreen World de Google, 60 % des internautes avouent débuter leur recherche sur mobile avant de la finir sur desktop. Par ailleurs, 88 % d’entre eux utilisent leur TV et leur smartphone en même temps.
Lire l’article
[Read More ...]
Thursday, 5 July 2018
Une introduction au Machine Learning en SEO / AEO
Qu’est-ce que le Machine Learning ?
Les citations suivantes résument très bien le Machine Learning.
Plus fluide
“Le Machine Learning est quelque chose de nouveau sous le soleil : une technologie qui se construit elle-même.”
Pedro Domingos
Plus intuitif
“Le Machine Learning est autant un art qu’une science. C’est comme la cuisine – oui il y a de la chimie, mais pour faire quelque chose de vraiment intéressant, vous devez apprendre comment combiner les ingrédients à votre disposition”. Greg Corrado, (Google)
Plus flexible
“Le machine learning n’est pas un bout de code statique : vous lui fournissez des données en permanence. Nous mettons constamment à jour les modèles et l’apprentissage, ajoutons plus de données et ajustons la manière dont nous allons faire des prédictions. C’est comme si c’était une chose vivante. Il s’agit d’une différente sorte d’ingénierie.” Christine Robson (Google)
Cool !
Toutes ces citations de sources anglophones proviennent de ce super article.
Le machine learning c’est comme cuisiner
Cuisiner : des ingrédients, des équipements de cuisine et un flair pour la cuisine.
Machine learning : des données, des mathématiques et une intuition d’ingénieur.
Machine learning vs Code traditionnel
Alors que le développement du code traditionnel est plus semblable à une science statique, le machine learning est un “être” fluide. À chaque fois que nous posons une question (input) pour obtenir une réponse (output), le chemin pour retourner la réponse est unique, écrit à la volée par une machine qui a été guidée par des ingénieurs plutôt que codée en “dur”. Et à chaque fois qu’elle remplit une tâche, elle apprend et peut appliquer ce savoir pour accomplir cette tâche encore plus efficacement la prochaine fois.
Époustouflant.
Les types basiques de machine learning
Le machine learning supervisé : fournir des données labellisées et fiables à une machine et lui indiquer les résultats attendus. Ensuite, on lui demande de trouver la formule optimale pour obtenir le résultat désiré à partir de ces données. Une fois que la formule a été définie, nous pouvons lui fournir des données non labellisées du même type et obtenir des prédictions fiables. AlphaGo est un excellent exemple : pour apprendre à jouer à Go, Google l’a alimenté avec plus de 10 millions de jeux humains. En analysant ces jeux la machine a identifié une stratégie et a pu battre le champion du monde.
Le machine learning non-supervisé : donner à la machine une gamme d’outils basiques, une source de données et un résultat désiré et laisser la machine labelliser les données et trouver la meilleure formule. AlphaGo Zero est un très bon exemple de cela – Google ne lui a fourni que les règles et le but du jeu Go, puis la machine a joué contre elle-même des millions de fois. Il lui a fallu seulement 2 jours pour apprendre à jouer suffisamment bien pour battre son prédécesseur AlphaGo 100 fois d’affilée.
Donc, dans un jeu avec des règles précises, Google a la capacité d’utiliser de l’apprentissage non supervisé et de surpasser 4 000 années d’efforts humains en seulement quelques jours.
Et cela n’est qu’une petite “mise en bouche” des progrès théoriquement possibles dans les années à venir.
Attention : Bien que le non-supervisé soit l’Eldorado du machine learning, Google ne risque pas de l’appliquer à grande échelle dans la sphère du SEO / AEO : il serait très dangereux de laisser son business model à la merci d’une machine. Google se doit de maintenir un certain niveau de supervision.
Donc, en SEO et AEO (Answer Engine Optimisation / Optimisation pour les Moteurs à Réponse), nous sommes intéressés par quelque chose situé entre ces deux types de machine learning – le Machine Learning semi-supervisé.
Dans ce cas, Google construit une fondation d’apprentissage supervisée sur des données labellisées et fiables, puis étend l’auto-apprentissage en utilisant des données non-labellisées de manière semi-contrôlée.
Pourquoi cela devient-il aussi important ?
Même si le terme “Machine Learning” date des années 1950, le machine learning n’est possible que depuis quelques années car, pour fonctionner, il requiert une gamme d’outils et de technologies qui ne sont tous disponibles que depuis une dizaine d’années.
Ce sont des technologies tels que les CPUs multithread dédiés, le Big Data, le Big Query (SQL basé sur des vecteurs) qui nous ont permis d’entrer dans l’ère de Machine Learning. Le monde vient de changer de manière radicale !
Google est très clair à ce sujet : c’est aujourd’hui une entreprise “AI-first” (ancré dans l’Intelligence Artificielle). Consultez ce site pour en savoir plus.
Note : bien que ce ne soit pas strictement vrai, IA et machine learning peuvent être considérés comme des synonymes pour le reste de cet article.
Le Machine Learning change les règles du jeu
Amit Singhal, Head of Search chez Google depuis le début des années 2000, vient du monde des “Retrievers”. Les “Retrievers” sont des ingénieurs qui écrivent du code statique pour collecter, trier et classer des informations selon des règles. Ces règles sont donc définies par les humains. Étant donné le succès de Google sous sa direction, il est clair qu’Amit Singhal et son équipe de retrievers sont très, très forts. David Pablo Cohn, un ingénieur leader en machine learning chez Google depuis 2002 a déclaré :
“ Il s’est avéré que l’intuition d’Amit était la meilleure du monde et nous avons fait mieux en essayant de coder en dur tout ce qui passait par le cerveau d’Amit. Nous n’avons rien trouvé d’aussi bon que son approche”.
Mais en 2014, l’équipe machine learning de Google a réussi à fournir des résultats de qualité équivalente à ceux des “retriever”. Mieux, ils avaient de meilleurs résultats quand ils s’agissait d’identifier une seule et unique réponse (la bonne). Les Machine Learners ont pris le dessus, et Google s’est fixé une approche 100 % IA. Grâce à ses avances en Machine Learning, Google devient aujourd’hui un moteur à réponse, qui a pour but de fournir à ses utilisateurs LA réponse / solution unique (et objectivement la meilleure) à leur problème / question.
RankBrain : Machine Learning entre dans le coeur de l’algorithme en 2015
Lorsqu’il a été lancé en 2015, RankBrain était la première utilisation de Machine Learning dans son algorithme annoncé par Google. Au lancement, RankBrain visait à améliorer les 15 % de requêtes que Google n’avait jamais vu auparavant. 9 mois plus tard, Google a annoncé que RankBrain affectait 100 % des recherches et était devenu le 3ème facteur de classement le plus important.
Cela montre clairement que, déjà en 2016, le Machine Learning était fiable et performant. Google ne fournit que très peu d’informations concrètes, mais au cours des deux dernières années, d’autres implémentations de Machine Learning ont certainement eu lieu. D’après mon opinion, nous avons également eu des mises en application Machine Learning de taille dans l’algorithme début 2018.
3 mises à jour majeures de l’algorithme en 2018
Début 2018, la plupart des outils de tracking (SEMrush, Mozcast, RankRanger) ont enregistré 3 secousses prolongées dans la volatilité des SERPs (j’exclu de mon analyse la mise à jour de l’index Mobile First du 22 mars puisqu’il s’agit d’un cas à part).
- Secousse d’une semaine en Janvier 2018
- Secousse d’une semaine en Mars 2018
- Secousse d’une semaine en Avril 2018
Pour les analyses, j’ai utilisé les chiffres de SEMrush Sensor d’avril 2017 à avril 2018. Un Sensor Score de plus de 7 sur leur échelle est considéré comme une mise à jour, et je calcule le score moyen sur une semaine pour donner un “score de secousse”. Il n’y a pas énormément de données mais les résultats sont plutôt évoquants.
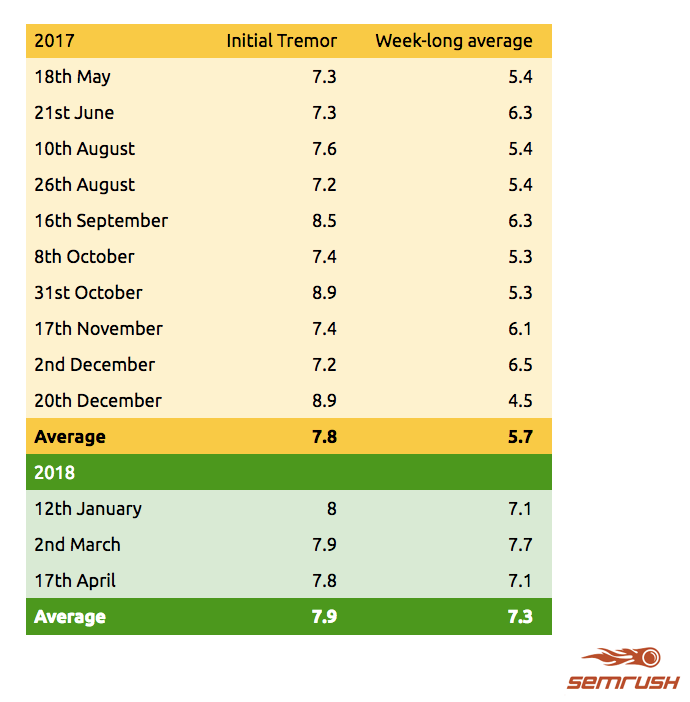
Données fournies par semrush.com
Les mises à jour en 2018 sont largement plus fortes qu’en 2017
- 2017 = 10 mises à jour, avec une secousse moyenne sur une semaine de 5.7
- 2018 = 3 mises à jour, avec une secousse moyenne sur une semaine de 7.3
La secousse moyenne est 30 % plus élevée en 2018 qu’en 2017. La moyenne des 3 mises à jour en 2018 est au dessus des 7, tandis qu’aucune des 10 mises à jour en 2017 n’a dépassé les 6.5.
3 mises à jours significatives de l’algorithme principal en 4 mois avec des périodes de volatilité inhabituellement longues. Google ne nous dit qu’une chose – ces mises à jour n’avaient pas pour objectif de pénaliser les sites de faible qualité… Dans ce contexte, ce commentaire prend un tout nouveau sens pour moi :
“Il y a toujours eu cette bataille entre les retrievers et les équipes Machine Learning. Les machine learners ont finalement remporté la bataille”. Pedro Domingos
Assistons-nous à une plus grande introduction de Machine Learning dans l’algorithme en 2018 ?
Google a précédemment annoncé que l’apprentissage en lui-même était fait offline.
Danny Sullivan (qui travaille désormais pour Google) : “Tout l’apprentissage que fait RankBrain est fait offline… On lui fournit des données de recherches historiques et il apprend à faire des prédictions à partir de ça. Ces prédictions sont testées et si elles sont bonnes, alors la dernière version de RankBrain est mise en ligne. Puis, le cycle d’apprentissage offline => test est répété.”
Considérant cette manière de fonctionner, les MAJ des 12 janvier, 2 mars et 17 avril sont peut-être des mises à jour “normales” de Machine Learning. Google pousse un élément de Machine Learning dans l’algorithme principal, créant un choc initial majeur qui est immédiatement suivi d’une période d’instabilité significative pendant que le nouvel apprentissage s’adapte aux données du monde réel.
Moteur à Réponse “à la Star Trek”
“La destinée du moteur de recherche Google est de devenir cet ordinateur de Star Trek, et c’est ce que nous sommes en train de construire”. Amit Singhal
Qu’est-ce qui rend l’ordinateur de Star Trek aussi intéressant pour Google ? Il fournit des réponses, soit après un échange conversationnel avec l’utilisateur, ou (même plus excitant pour Google) en anticipant les besoins de l’utilisateur et fournissant la solution sans même avoir été sollicité.
Google s’est donné pour mission de développer un Assistant Virtuel qui dialogue avec les utilisateurs, observe leur comportement, apprend de manière autonome, s’améliore au fil du temps et fourni des réponses uniques (objectivement correctes)… le tout étayé par du Machine Learning.

Google est destiné à devenir un moteur de réponse “à la Star Trek”.
Le Machine Learning – les deux parties de l’équation AEO
Note : ils est évident que la délimitation les deux parties de l’équation n’est pas aussi claire que suggérée ci-dessus. Mais cette distinction permet de fournir une approche relativement simple qui permet d’aborder le court terme, sans perdre de vue le long terme.
- Front end : comprendre l’intention de l’utilisateur
Ici, l’implémentation du Machine Learning est déjà bien avancé via RankBrain – modèles de requête, vecteurs de mots, codage universel de phrases etc. Il s’agit de la partie de l’algorithme destinée à mieux comprendre le besoin de l’utilisateur, et donc de permettre au moteur de recherche de mieux prioriser les résultats selon ses intentions.
Pour toutes les recherches effectuées sur Google, RankBrain prend la requête, y ajoute les informations dont il dispose sur l’utilisateur (l’historique de recherche, les attributs de la personne, l’historique d’achat etc.), le contexte spécifique (l’heure, la localisation, l’appareil etc.) et sa compréhension des entités pour identifier la véritable intention derrière les mots utilisés dans la requête.
Objectif : comprendre l’intention de la question / le fond du problème exprimé afin de communiquer au back end un besoin / question très spécifique et explicite.
- Back end : comprendre les solutions disponibles
Google rassemble des informations sur le monde à travers plusieurs canaux : le Knowledge Graph, MyBusiness, Local Guides, Adwords… avec l’objectif de fournir au front end la réponse / solution la plus pertinente et crédible. Le but du back-end est de collecter et comprendre de manière fiable les options disponibles, puis d’évaluer leur crédibilité et pertinence pour identifier la meilleure réponse.
Il s’agit d’un vaste territoire où le Machine Learning dispose d’un grand nombre d’applications possibles et s’installe sur le devant de la scène. Bien qu’ils restent très évasifs dans leurs notices officielles, les brevets de Google indiquent que le Machine Learning est déjà appliqué dans cette sphère, et est destiné à devenir la force dominante. Les articles de Bill Slawski sont une très bonne source d’informations et d’inspiration sur ces brevets. Vous pouvez commencer à les lire ici.

Objectif : fournir LA bonne réponse au problème exprimé
Nous devons changer notre approche
Le Machine Learning est un “game changer” : nous vivons actuellement une véritable révolution en SEO.
Au lieu de se demander “Comment être parmi les possibilités offertes par Google à ses utilisateurs” (les 10 liens blues), nous devons maintenant nous demander “Comment être la réponse unique fournie par Google à un utilisateur pour le problème qu’il a exprimé”.
Ce changement de perspective est nécessaire dès aujourd’hui. Les nouvelles opportunités pour être cette réponse unique sont déjà en place et sont à prendre – AnswerBoxes, Knowledge Panels, Autres Questions Posées, MyBusiness etc (autrement dit, des Position0). La montée de la recherche vocale va augmenter considérablement l’importance de la Position0, pour le rendre indispensable dans une stratégie digitale.
Se tenir informer et mettre en œuvre des tactiques efficaces pour gagner la Position0 est déjà une tâche extrêmement difficile, mais cette tâche deviendra plus difficile encore dès lors que le machine learning fera de ces Position0 des résultats ultra-personnalisés, au cas par cas et en temps réel.
Implémenter les tactiques pertinentes est, bien sûr, nécessaire. Mais dans le contexte de “Révolution Machine Learning”, prétendre être LA réponse unique offerte par Google, Microsoft ou Amazon demande une approche holistique, centrée sur la marque.
Le Machine Learning nous mène dans la nouvelle ère des moteurs à réponse. La stratégie gagnante en AEO (optimisation pour les Moteurs à Réponse) sera obligatoirement centrée sur la Compréhension et la Crédibilité.
Plus sur le AEO par Jason Barnard
Le futur du SEO / AEO : compréhension et crédibilité
Graphe de connaissance Google – Qu’est-ce que c’est ? Comment en profiter ?
[Read More ...]
Wednesday, 4 July 2018
L’avenir de la mobilité à Québec mobilise plus de 10 000 citoyens!
Québec, le 4 juillet 2018 – La Ville de Québec dépose aujourd’hui le rapport de consultation publique portant sur le projet de réseau structurant de transport en commun. Au total, c’est plus de 5 000 personnes qui ont assisté, sur place ou par webdiffusion, aux cinq séances d’information et de consultation qui se sont tenues les 4, 5, 7 et 11 avril 2018, pendant lesquelles 200 personnes majoritairement favorables au projet ont exprimé des commentaires ou posé des questions. De plus, 5 209 citoyens ont répondu au questionnaire en ligne au cours du mois d’avril.
Principaux thèmes abordés lors des séances d’information et de consultation :
- Desserte de la couronne nord de la ville et de l’arrondissement de Beauport;
- Importance de l’accessibilité universelle des infrastructures et du matériel roulant;
- Impacts sur l’aménagement du territoire et sur les résidences riveraines des tracés du tramway et du trambus;
- Fiabilité et rapidité des temps de parcours à la suite de la mise en service du réseau structurant;
- Partage sécuritaire de la chaussée entre tous les usagers de la route (piétons, cyclistes et automobilistes) et le tramway;
- Effort de communication et d’information de la Ville à maintenir.
Quelques faits saillants sur le questionnaire en ligne[1] :
- 57 % des répondants sont totalement ou plutôt satisfaits du projet dans son ensemble;
- 57 % des répondants estiment que le projet répond aux besoins des citoyens;
- Plus de la moitié des répondants sont satisfaits pour les tracés proposés du tramway (56 %) et du trambus (55 %);
- Plus de répondants projettent d’utiliser le transport en commun pour se rendre au travail (de 32 % en 2018 à 40 % en 2026), pour des déplacements de loisirs (de 44 % en 2018 à 52 % en 2026) ou pour le magasinage (de 19 % en 2018 à 30 % en 2026);
- 70 % des répondants sont satisfaits de l’amplitude de l’horaire (5 h à 1 h) offerte par le réseau structurant;
- 65 % des répondants croient que les temps de déplacement seront fiables et 53 % croient qu’ils seront plus courts.
Le rapport de consultation est disponible sur le site Internet de la Ville de Québec à https://www.ville.quebec.qc.ca/reseaustructurant, dans la section Documentation.
Travaux en cours et prochaines étapes du projet
Rappelons que la Ville de Québec procède actuellement à une collecte de données complémentaires et préliminaires (relevés d’arpentage, sondages des sols et localisation des utilités publiques) nécessaires à l’avancement du projet. La Ville sera donc en mesure, dans les prochains mois, de répondre aux préoccupations des citoyens par rapport à l’impact de l’implantation du réseau structurant sur leur propriété. Des rencontres spécifiques seront tenues au moment opportun. Les citoyens concernés en seront les premiers informés.
Par la suite, les études de conception (2018-2019) seront réalisées. Ces études consistent à préciser l’insertion de l’ensemble des tracés proposés dans le projet. Enfin, la Ville élaborera les plans et devis (2020-2022) pour finaliser de façon plus précise l’ensemble des besoins en infrastructures et en matériaux pour la mise en chantier du projet, prévue pour 2022.
À propos du réseau structurant de transport en commun
À la suite des consultations de juin 2017, les citoyens se sont prononcés à une forte majorité en faveur d’un réseau structurant de transport en commun. Le projet présenté par la Ville de Québec en mars 2018 comportera quatre composantes, soit le tramway (23 km, dont 3,5 km en souterrain), le trambus (17 km), les infrastructures dédiées au transport en commun (16 km) et le Métrobus (110 km). L’ensemble des parcours du Réseau de transport de la Capitale (RTC) se connectera à ces composantes pour assurer une couverture maximale sur le territoire. La Ville de Québec vise une mise en service complète d’ici 2026.
Pour accéder à beaucoup de documentation (photos, vidéos, foire aux questions, historique de la démarche, caractéristiques des modes de transport, etc.), les citoyens sont invités à consulter le ville.quebec.qc.ca/reseaustructurant.
[1] Ces données correspondent aux répondants résidant dans l’agglomération de Québec. Il ne s’agit pas d’un sondage représentatif de la population.
[Read More ...]
Tuesday, 3 July 2018
Entités et SEO : une introduction complète
Vous avez déjà du tomber sur le détecteur d’entités nommées d’OnCrawl ou sur l’un des articles d’Emma sur le Knowledge Panel de Google en vous demandant ce qu’était exactement une entité. Si vous n’êtes pas familier avec le terme ou ce qu’il signifie alors prenez note : c’est le moment de plonger dans le sujet. Les entités sont sans un doute l’une des idées les plus puissantes du search.
Je vais prendre des risques et prédire que dans un futur prochain les entités vont surpasser les liens et le contenu en tant que domaine clé pour les SEOs et tous ceux qui cherchent à obtenir des classements. Cependant, comme nous allons l’aborder, les entités reposent sur ces deux facteurs pour construire leur influence. Dans cet article, nous allons observer comment utiliser les liens et le contenu pour renforcer et connecter les entités.
Super… Mais qu’est-ce qu’une entité ?
A ce stade, vous n’êtes pas plus avancé que lorsque vous avez lu le titre. Dans un premier temps, je voulais souligner l’importance des entités dans le search. Maintenant, nous allons plonger dans leur définition, puis j’illustrerai ces déclarations et mettrai en avant quelques approches pour vous aider à utiliser ces informations afin de sauvegarder ou construire vos classements dans le futur.
Commençons avec la définition de Google issue de l’un de leur brevets sur le sujet (oui – il y a plusieurs brevets) :
Entité : une chose ou concept qui est singulier, unique, bien défini et distinguable.
Donc, est-ce que cela clarifie les choses ?
J’ai longtemps pensé aux entités comme à des noms (une personne, un endroit ou une chose). J’avais tort, elle vont bien au-delà de ça. Une entité peut être une idée, un adjectif, un concept… Tout ce qui peut être défini de manière unique. La couleur rouge par exemple. Ou le théorème de Pythagore. Ou cet article. Ou le concept des entités. Ou un mot du concept. Ou une lettre de ce mot. Ou un pixel de cette lettre. Tout. Même un auteur qui n’a toujours pas précisément abordé son sujet au bout de 300 mots.
Alors, quel est le but, Dave ?
Observons le nom de Dave comme une entité. En fait, ‘Dave Davies’ est une entité. Il y en a 4 (au moins) dans ma ville. Il y en a 3 rien que dans cette photo :

Chacune de ces entités a une connexion. Elles sont toutes nommées Dave Davies. Elles ont d’autres traits similaires comme le genre ‘masculin’ et bien d’autres similitudes mais leurs points de différenciation sont bien plus nombreux. Et c’est à ce stade que les entités apparaissent.
Utilisons comme exemple le très célèbre ‘Dave Davies’ dans cette image et observons une illustration basique de l’entité ‘Dave Davies’ du groupe The Kinks. Si vous ne le connaissez pas, voici de qui nous parlons :
Maintenant, jetons un oeil à une petite partie de son graphique d’entités que vous pouvez voir sur cette illustration basée sur l’un des brevets de Google et conçue pour notre exemple :
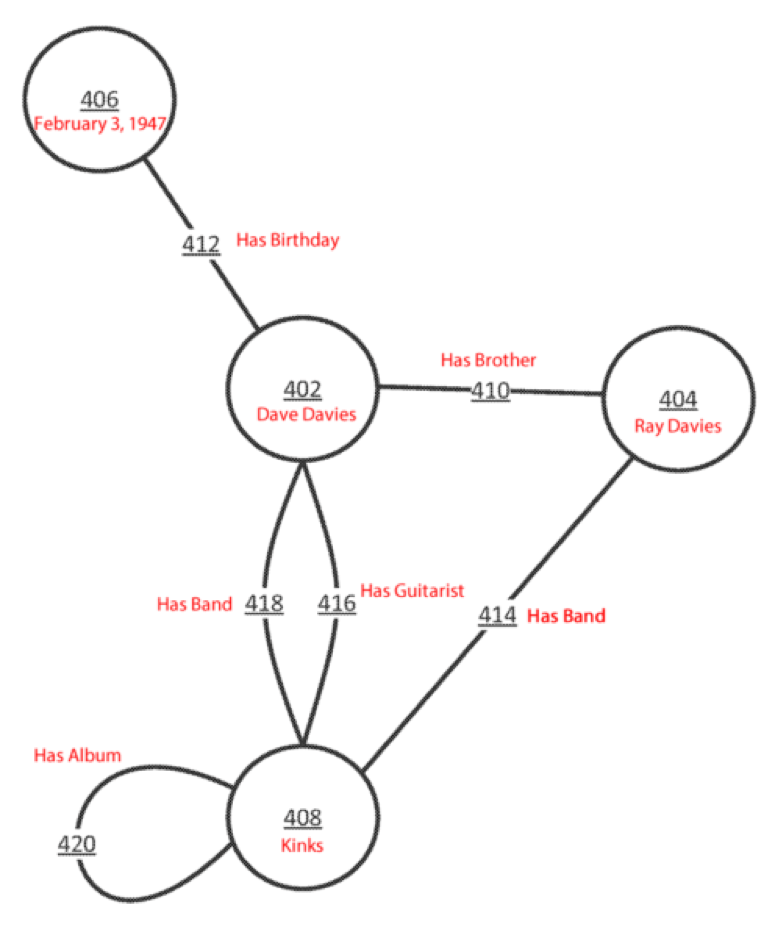
Ce que vous pouvez facilement voir ici est le graphique des entités (les cercles) et leur relation (les lignes). Si le tracé de ces relations vous semble familier c’est probablement parce qu’il ressemble beaucoup à :
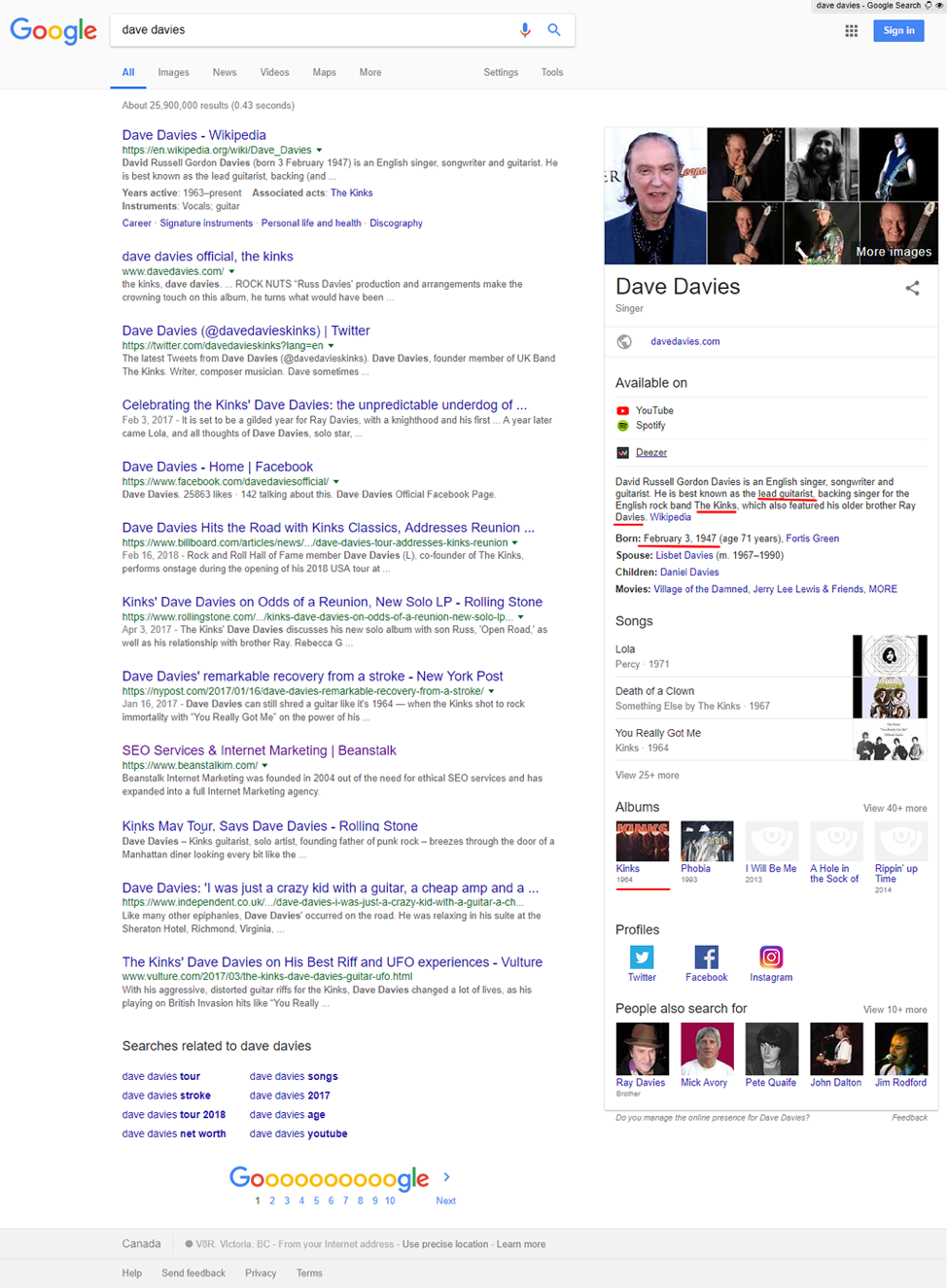
Vous commencez à voir les connexions ? Les Knowledge Panels sont juste la partie immergée de l’iceberg mais elles font un excellent exemple visuel des entités et de leurs relations utilisées directement dans le search.
Que pensez-vous que Google utilise lorsqu’il répond aux recherches “à proximité” ? Google a besoin de comprendre spécifiquement la relation entre un site web ou n’importe quelle autre source de données, une entreprise et ce qu’elle offre pour obtenir un résultat comme celui-ci :
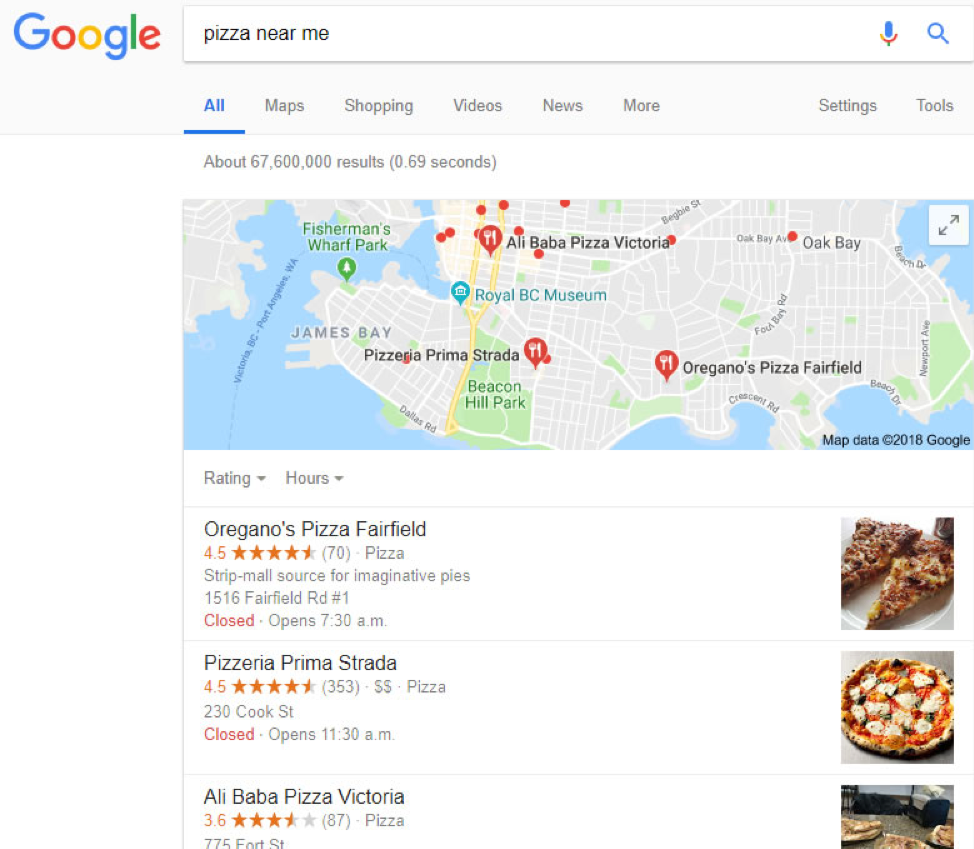
Google doit comprendre l’entité de la localisation, des entreprises, les nombreux attributs d’entité (notes, images, ect…) qui sont aussi des entités en elles-mêmes puis connecter ces entités d’entreprise à l’entité “pizza”.
Donc, nous pouvons voir grâce à ces quelques exemples, l’utilité des entités et leur relation dans les recherches locales et les Knowledge Panels. Les nombreux brevets de Google sur le sujet approfondissent encore plus le sujet.
Google et les liens
Mais alors, pourquoi Google s’intéresse aux liens ? Il s’y intéresse parce qu’il les traite comme un “vote” d’un site vers un autre. Ce qu’il cherche réellement à faire (bien que les équipes de Google ne le savaient pas lorsqu’ils ont créé PageRank) est de comprendre la relation entre une entité (le site lié) et la cible (le site lié à). Et ils ont commencé à incorporer d’autres facteurs comme le PageRank ou le maillage d’un site (le score PageRank est une entité), l’ancre de texte utilisée (entité), la pertinence du sujet (le sujet est aussi une entité), et bien d’autres (excusez-moi, ils ne m’ont pas fourni leur liste de facteurs PageRank ou je l’aurais inclue dans l’article).
Tout ce travail sur les liens avait pour but de répondre à une question basique : Comment une entité est liée à une autre ?
Donc, la question que nous pouvons nous poser est : si Google obtient une meilleure compréhension des entités que celle qu’il a des liens, utiliserait-il les liens ?
La réponse courte est non, ou du moins pas dans le contexte dans lequel nous le voyons aujourd’hui. Il pourrait les utiliser pour confirmer les associations mais pas comme facteur principal.
Mais pourquoi Google… Pourquoi ?

Et pourquoi ferait-il cela ? La réponse est simple si vous pensez à la manière dont vous utilisez vos appareils. Nous avons nos ordinateurs, bien sûr, mais nous avons aussi nos portables, Google Homes, nous voulons regarder nos vidéos sur nos télés, nous voulons que Google sache où nous sommes dans le temps et l’espace et nous dirige vers notre destination aussi vite que possible, nous voulons que Google nous dise ou la pizzeria la plus proche se situe… Nous le demandons, c’est pour ça.
Considérons un instant les SERPs en eux-mêmes. Tous ces Featured Snippets, Knowledge Panels, réponses… ces formats sont seulement possibles grâce à la compréhension de Google de la manière dont les entités se connectent.
Que pouvez-vous faire ?
J’espère que je vous ai aidé à comprendre les entités et surtout que je vous ai donné envie de garder vos yeux et vos oreilles ouverts pour plus d’informations. Il ne s’agit pas d’un domaine du SEO très technique. Je le reconnais, qu’il peut l’être mais pas plus que le maillage, les stratégies de contenu ou l’analytics. En attendant, que pouvez-vous faire pour améliorer la valeur de votre entité ?
Cette question a plusieurs réponses. Améliorer la valeur de votre entité qui est votre site web (qui contient lui-même un nombre incalculable d’entités) demande simplement de renforcer votre valeur et les relations entre les entités que vous souhaitez associer.
- Créer du contenu qui ne parle pas simplement de vos produits et services mais aussi des sujets liés à votre site. Du contenu qui permet de renforcer l’association de votre site et du sujet pour lequel vous souhaitez vous classer. Cela va avoir le bénéfice secondaire d’améliorer vos chances que Google considère votre site comme une réponse aux intentions des utilisateurs.
- Construire des liens fiables et faire en sorte que votre marque et votre site soient mentionnés sur les pages pertinentes. Les liens sont mieux que les mentions mais comme Google travaille de plus en plus dur pour comprendre votre entité, il est possible (si j’ose dire probable) qu’il n’ait plus besoin de liens pour faire l’association entre les entités.
- Ajouter un schéma à votre site. Un schéma est un moyen très simple d’ajouter des informations à votre site pour préciser votre lien avec des sujets, marques, produits ou services spécifiques et bien d’autres bénéfices.
- Garder votre Google My Business mis à jour. Si vous n’avez pas de listing Google My Business, vous devriez probablement vous y mettre dès maintenant au lieu de lire cet article (mais vous avez presque fini alors vous pouvez attendre la fin de l’article avant de le faire). C’est là que vous fournissez spécifiquement à Google une tonne d’informations à propos de votre site, de votre entreprise, de la pertinence de votre sujet et d’autres détails. Vous pouvez aussi l’utiliser pour ajouter des informations supplémentaires dans votre Knowledge Panel afin d’apporter plus de détails aux utilisateurs.
Il y a encore beaucoup de choses importantes à savoir sur les entités, nous avons seulement balayé la surface. Prêtez attention à ce qu’il se passe avec les supports et à tout ce que vous entendez à propos des entités. C’est le futur.
Maintenant, allez vous chercher une entité qui est du café à l’intérieur d’une autre entité qui est la tasse comprenant une relation à l’entité qui est votre température préférée et lancez-vous !
[Read More ...]
Monday, 2 July 2018
Sunday, 1 July 2018
#SiteWebQuebec Le référencement naturel ou SEO (Search Engine Optimization) englobe lensemble des méthodes et techniques...
#SiteWebQuebec Le référencement naturel, ou SEO (Search Engine Optimization), englobe l’ensemble des méthodes et techniques...
— Jonathan Loiselle Media (@LoiselleMedia) July 1, 2018
de Twitter https://twitter.com/LoiselleMedia
June 30, 2018 at 10:19PM
via Jonathan Loiselle Media | Creation de Site Web et Marketing Web a Quebec
[Read More ...]
Subscribe to:
Comments (Atom)
3 facteurs qui éloignent les utilisateurs et les crawlers de votre page d’accueil
Votre page d’accueil n’est pas juste un espace dans lequel vous affichez votre nom de marque et votre logo. Il s’agit de la page initial...

-
#SiteWebQuebec https://t.co/84mWzukoJB conception site web levis — Jonathan Loiselle Media (@LoiselleMedia) March 23, 2018 de Twitte...
-
À l'occasion du temps des Fêtes, tous les bureaux municipaux seront fermés du 24 décembre au 2 janvier inclusivement. Toutefois, le Cent...
-
Nous sommes très heureux de vous proposer un ensemble de nouvelles améliorations pour rendre l’analyse de vos crawls et l’interprétation des...
