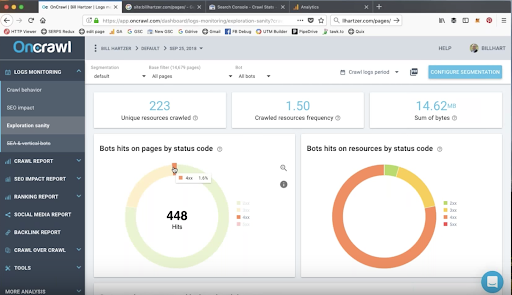
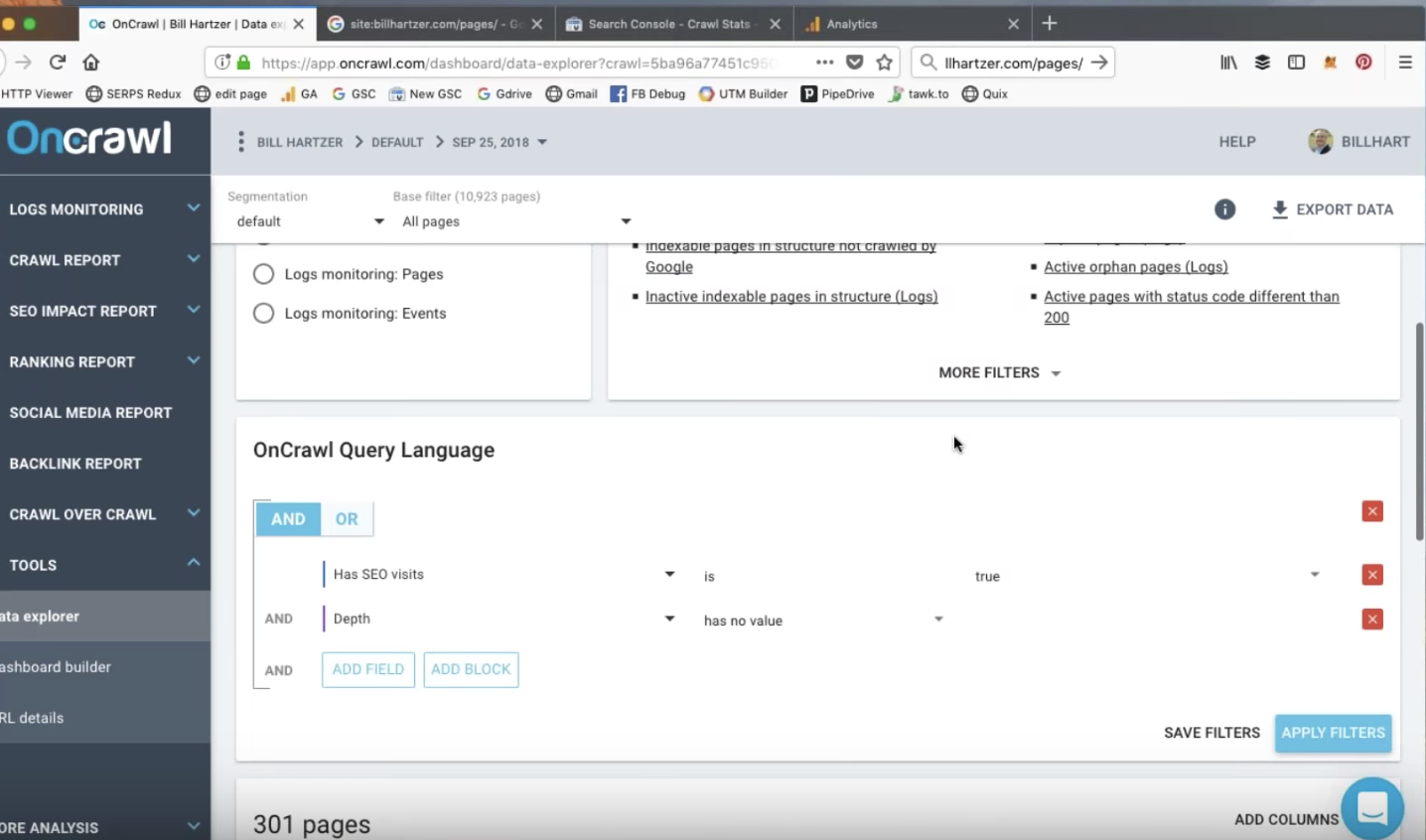
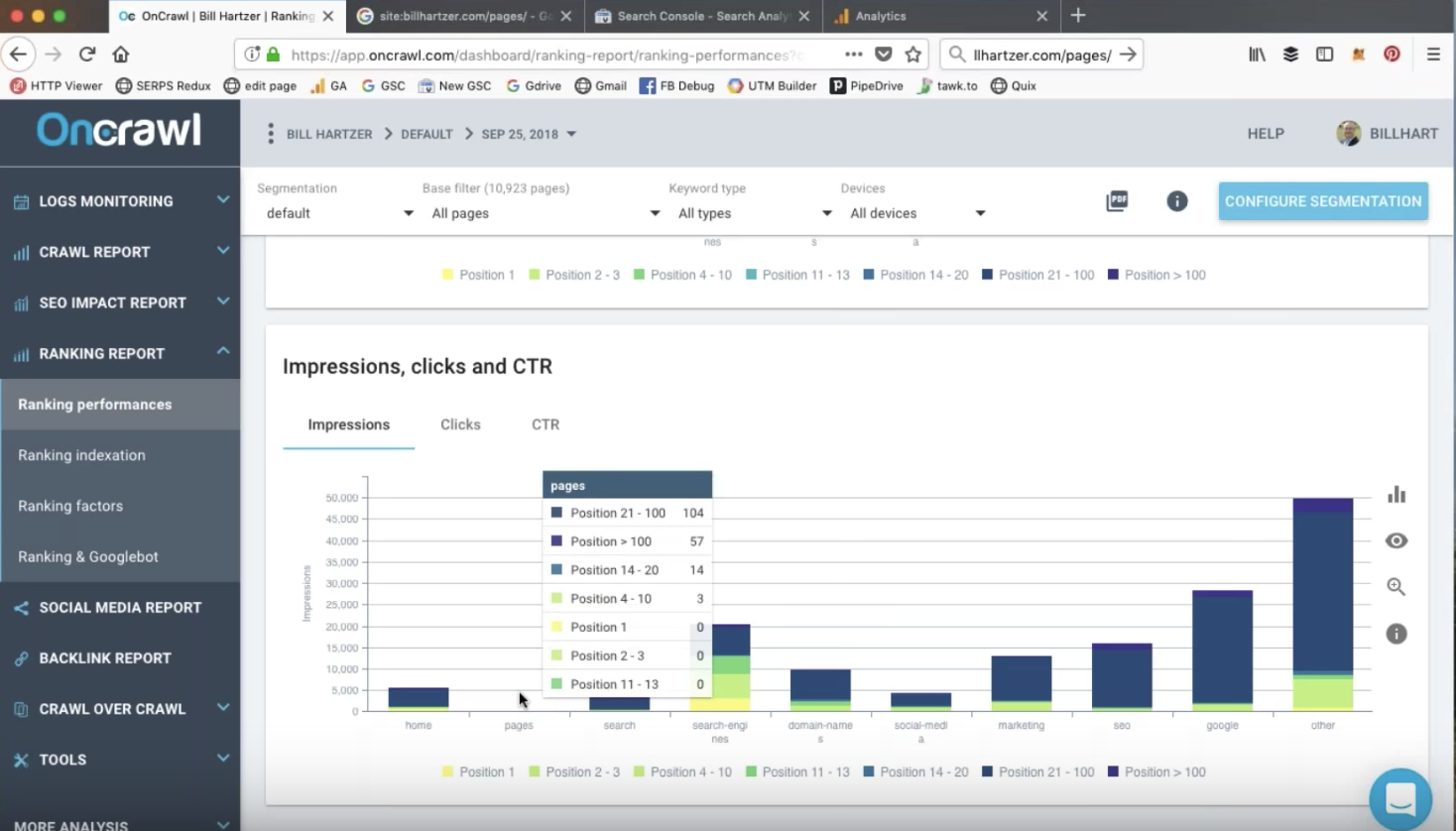
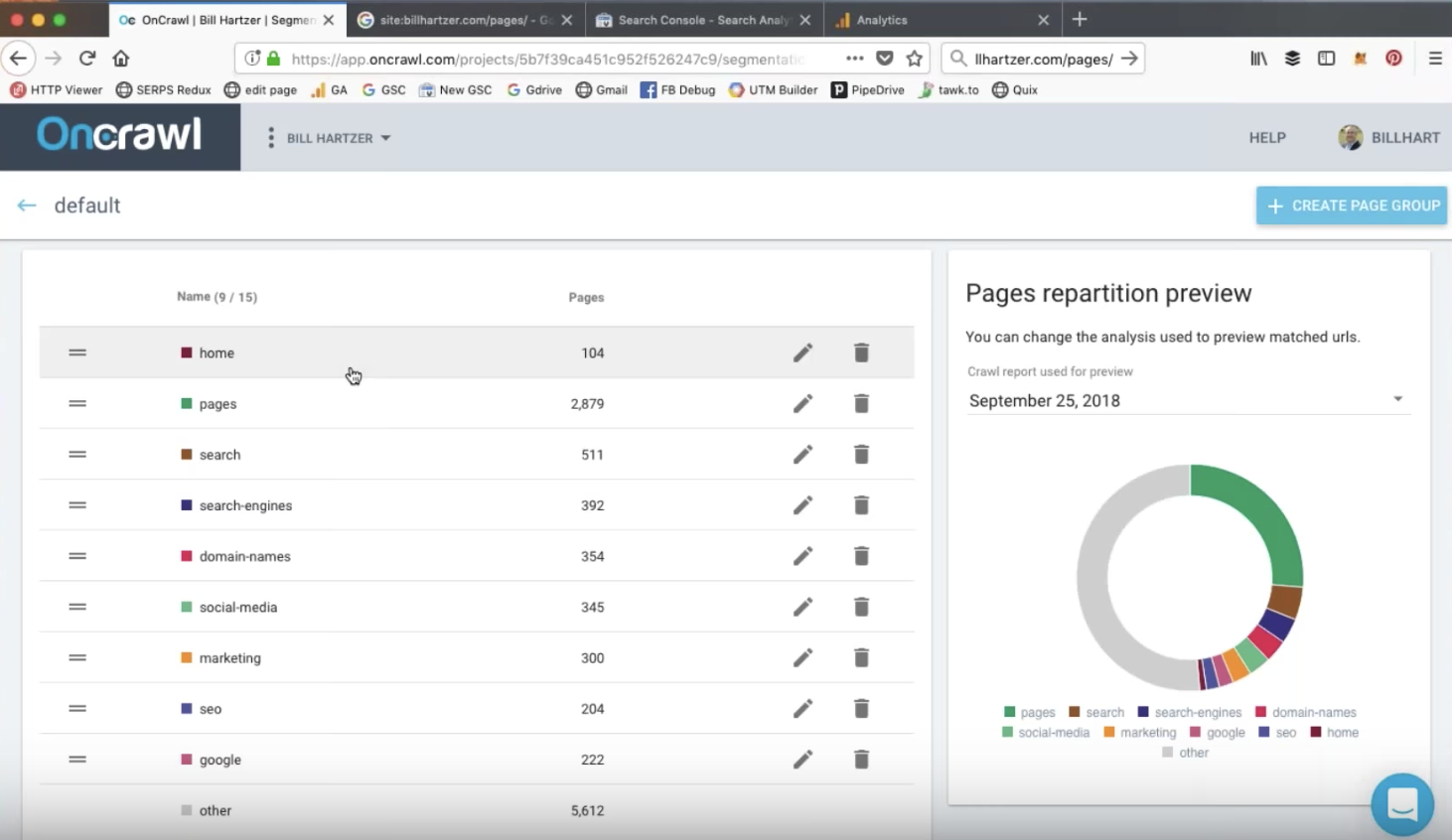
Un petit bout de code à la mauvaise place. Une structure de site web mal pensée. Un slash manquant sur un lien interne. Tout cela semble complètement innocent. Pourtant, si vous travaillez dans le milieu du SEO technique, ces petites erreurs vous donneront des frissons ! Je réalise des audits de sites depuis des années maintenant et j’ai vu de nombreuses horreurs en termes de SEO technique. Soyez prévenus, je vais revenir sur certaines des erreurs techniques les plus communes dans les prochaines lignes. Cet article n’est pas pour les froussards !
Le cas du site web disparu
Heureusement, ce n’est pas quelque chose dont je suis coupable, mais j’ai été confrontée à ce cas précédemment.
Un prospect vous consulte avec une situation déroutante : leur site se classait très bien sur certains mots-clés à fort trafic, mais après une migration, il est devenu introuvable dans les résultats de recherche.
Je vérifie les facteurs classiques, “est-ce que des redirections ont été implantées” et “est-ce que le sitemap XML a été ajouté à la Google Search Console”, mais cela ne m’apporte aucune solution.
J’ai ensuite vérifié le robots.txt et tout est devenu plus clair ! Dans une tentative de préserver l’invisibilité du site lors de son développement, une commande “disallow” a été ajoutée au robots.txt. Ces deux lignes de code simples : “User-agent:*Disallow:/” ont été oubliées lors du lancement du site et ont rendues complètement impossibles les visites des bots sur ce site qui obtenait pourtant de très bons classements. La réparation est rapide et très simple mais les résultats peuvent être dévastateurs si le code a été laissé trop longtemps.
Je suis confrontée à des sites avec ce problème depuis un an. Vous pouvez imaginer l’état de leurs classements avant que l’erreur soit découverte. Heureusement, voir ce type d’erreurs sur des sites m’a rendue très vigilante lorsque j’accompagne le lancement d’un nouveau site. Ce n’est vraiment pas une erreur que je veux faire !
Je conseille toujours de mettre en place une checklist robuste avant le lancement d’un site. Cela aide à s’assurer que tous les items cruciaux sont bien assurés et que rien n’a été oublié. Assurez-vous que vous continuez de mettre à jour cette checklist avant chaque lancement de site pour empêcher ces problèmes nuisibles comme les “disallow” oubliés.
Les redirections égarées
Une tâche commune lorsque vous travaillez sur le SEO d’un site est de mettre en place des redirections. Que ce soit une seule URL renvoyant une 404 ou un site web entier migrant vers un nouveau domaine, il existe de nombreux cas ou une redirection est nécessaire. Le recensement des redirections est pour moi plutôt thérapeutique. C’est une tâche systématique, et s’il existe déjà une structure connue, cela ne demandera pas trop de travail.
Malheureusement, de part sa nature méthodologique, travailler sur une longue liste d’URLs qui ont besoin de redirections peut conduire à des erreurs. Si l’attention requise n’est pas au rendez-vous, une page peut facilement être redirigée vers une URL qui n’est pas vraiment pertinente, ou bien une chaîne de redirections peut accidentellement être créée.
Une amie très talentueuse m’a récemment confessé qu’elle avait redirigé les pages “panier” d’un site e-commerce vers la page d’accueil. Donc, aucune transaction ne pouvait être réalisée : une expérience véritablement terrifiante ! Cela arrive facilement, surtout si une liste de 404 a été chargée depuis la Google Search Console et n’a pas été correctement vérifiée pour déterminer si ces URLs étaient bien des pages actives.
Mon conseil ? Prenez soin de chaque URL lorsque vous réalisez des redirections. Si vous pensez qu’une URL renvoie une 404 et que c’est la raison pour laquelle vous réalisez une redirection, vérifiez cette théorie afin d’agir ! Si vous rediriger une URL dans le cadre d’une migration, échangez avec les développeurs et assurez-vous que les pages vers lesquelles vous redirigez vont bien exister lorsque le site sera en ligne
Spider trap : une situation récurrente
Le prochain exemple est malheureusement une situation courante sur le web et ce n’est pas quelque chose dont les audits SEO sont responsables : les spiders trap.
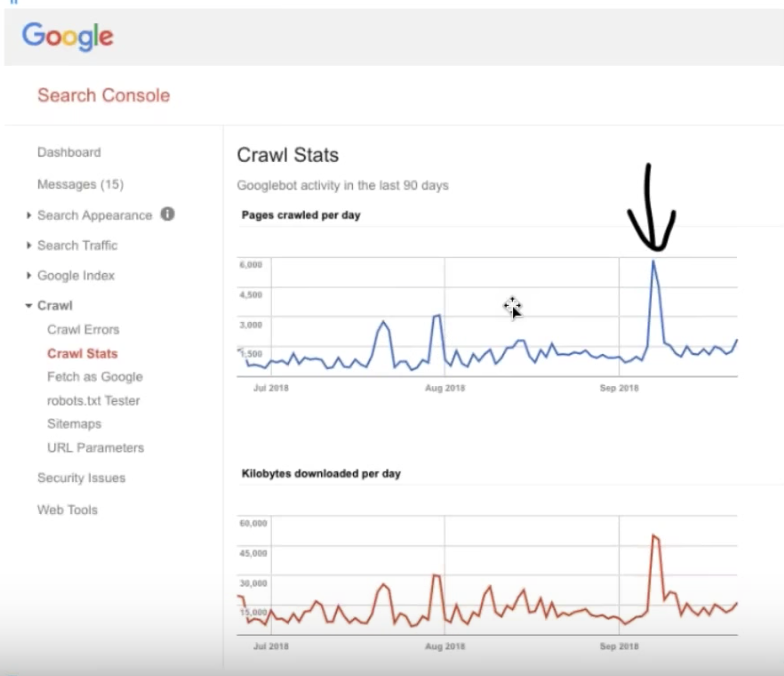
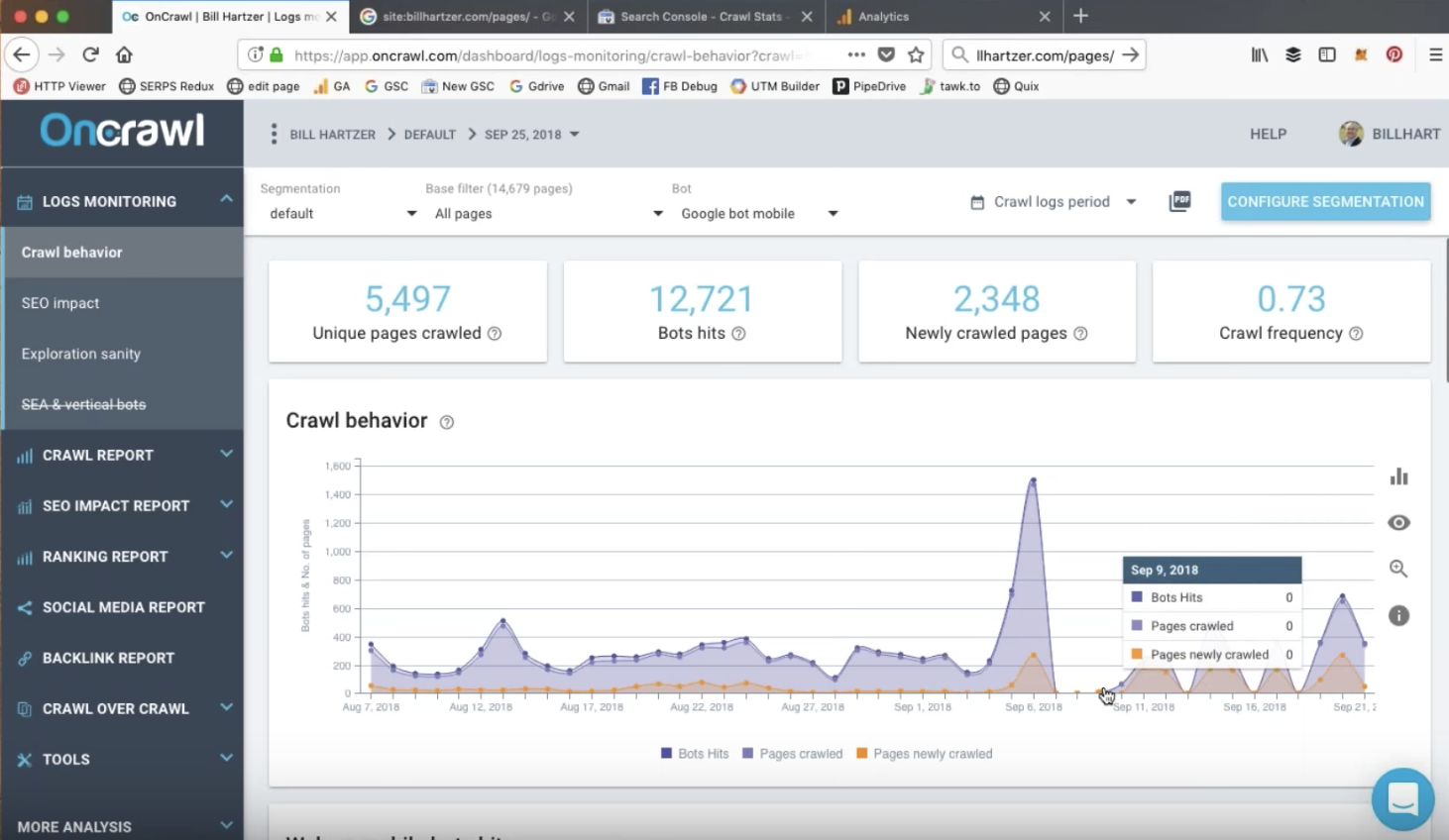
Vous pouvez les remarquer lorsque votre site web n’est pas encore volumineux, que vous avez eu le temps de partir en pause déjeuner et que le crawl est toujours en cours. Un spider trap est composé d’un groupe de pages sur un site web qui bloque le bot sur des pages à faible valeur.
Les pages créées automatiquement par des applications qui contiennent des liens vers des pages dynamiques sont souvent les causes des spider trap. Un widget calendrier par exemple peut avoir une page détaillant tous les événements en Janvier 2019 avec un lien qui permet aux visiteurs de cliquer pour voir une page avec les événements de Février 2019. Chaque page contient un lien vers la page des événements du mois prochain. Malheureusement, il peut ne pas y avoir de fin à ces pages et vous pourriez aller jusqu’en Avril 3530 si vous le souhaitiez !
Les bots sont conçus pour suivre des liens sur une page et pour découvrir d’autres pages. Même si un humain n’aurait pas la patience de cliquer sur le lien “voir le mois prochain”, un bot le ferait et continuerait à suivre les liens vers ces pages blanches jusqu’à temps que le temps autorisé sur cette page soit terminé.
Le problème avec les spider trap pour les moteurs de recherche, c’est qu’ils consomment le temps et les ressources des bots et les empêchent de visiter les pages à crawler et indexer. Ils peuvent aussi ajouter un grand nombre de pages de faible valeur aux listes de pages des bots, ce qui va faire diminuer la qualité globale du site.
Les spider trap sont plutôt faciles à repérer avec un crawler. Cependant, il peut être difficile de déterminer ce qui les a créé. Commencez par déterminer l’ancre de texte du lien qui dirige vers ces pages non voulues. Un fois qu’elle a été identifiée, il est bien plus simple de corriger ou d’ajouter une balise méta no-index si nécessaire.
La page morte-vivante
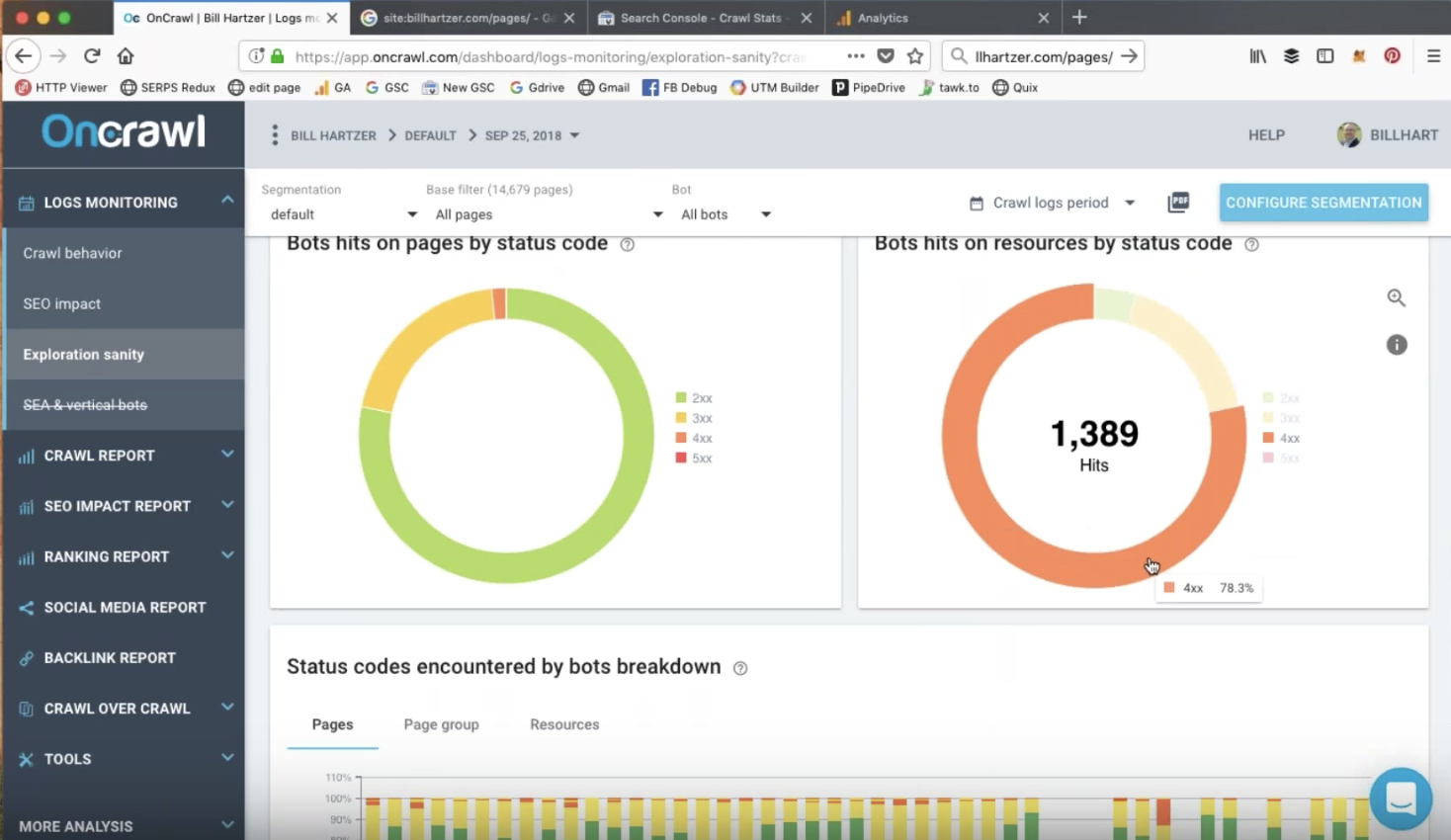
Les pages renvoyant une404 sont naturelle sur le web. Des produits non disponibles en stock, une page supprimée ou un lien vers une page qui n’existe pas : il existe de nombreux moyens de générer une404. Ces codes peuvent être frustrants pour les utilisateurs d’un site car ils ne sont pas en mesure de trouver la page qu’ils voulaient. Mais il y a des réparations qui fonctionnent dans cette situation, comme rediriger la page vers une autre plus pertinente ou même créer une page 404 personnalisée qui aide les utilisateurs à naviguer vers la page qu’ils attendaient.
J’ai relevé d’étranges pratiques au cours des dernières années pour s’assurer de la suppression de pages 404. J’ai constaté un nombre inquiétant de sites web employant des redirections automatiques pour toutes les pages renvoyant un code 404. Plutôt que d’identifier les meilleures pages pour rediriger chaque URL renvoyant en 404, ils redirigent automatiquement vers la page d’accueil, ou pire vers une page “/404” mise en place pour imiter l’apparence d’une véritable page 404. Il y a aussi des cas ou une page devrait retourner une erreur 404 car la ressource originale qui devait être atteinte sur cette URL n’existe plus et que la page ressemble à une page d’erreur. Mais la réponse restait un code 200 “OK”. Cette page morte, est en faite, vivante.
Toutes ces tentatives pour composer avec une 404 sont loin d’être idéales. Renvoyez un code “OK” plutôt qu’une 404 (ou même un 410 “gone”) suggère aux bots que cette page est active et fait partie intégrante de votre site. Cela va pousser les bots à crawler cette page de faible qualité et peut-être même à l’indexer.
Les meilleurs pratiques pour gérer ces pages sont simples. Si la page a une remplaçante alors redirigez-là vers cette URL. Cela va permettre aux utilisateurs de trouver une autre page qui leur sera utile et donnera aux bots une page utile à crawler et indexer. Si la page a été supprimée et ne sera jamais réhabilitée, alors vous pouvez tout à fait créer un code de réponse 410 “gone”. Cela informe les moteurs de recherche que la page ne reviendra pas et donc qu’il n’est pas nécessaire de continuer à la crawler. Cette possibilité n’offre pas à vos utilisateurs la meilleure expérience mais tant que vous les renvoyez vers d’autres pages qui sont pertinentes, cela ne devrait pas empêcher la poursuite de leur voyage.
Restez prudents
J’ai encore d’autres histoires terrifiantes d’erreurs SEO ! Il est crucial de s’assurer que les fondations techniques de vos sites web sont solides. Sinon, vous pourriez perdre beaucoup de temps à essayer de les positionner. Vous pouvez conduire des audits réguliers pour empêcher des changements dans le code ou des ajustements dans le contenu de causer des dommages. Rappelez-vous, un site web performant est le rêve d’un marketer mais un site criblé de problèmes techniques devient rapidement un cauchemar !
[Read More ...]